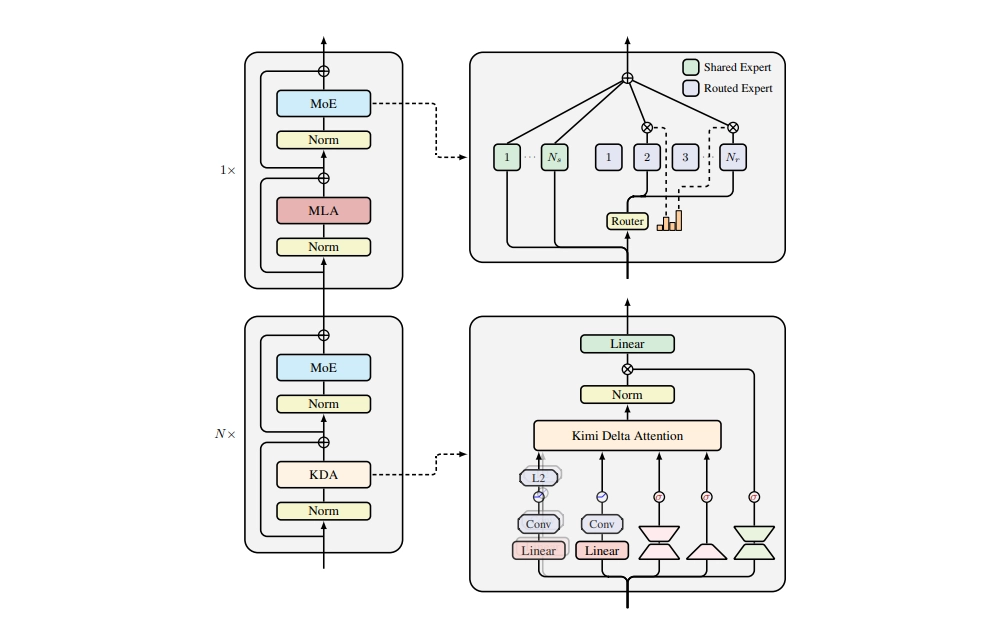
#Reinforcement Learning
50 articles with this tag
5 AI Research Papers Shaping AI's Future
Discover five key AI research papers that reveal the current trajectory and future directions of artificial intelligence development.

LifeSkill: LLM Agents Learn Continuously
LifeSkill framework enables LLM agents to continuously learn from test-time feedback, significantly improving performance on long-horizon tasks by internalizing skills.

AI Agents Automate Drone Navigation Rewards
AgenticRL framework uses AI agents to autonomously design rewards and refine policies for UAV navigation, achieving 91% real-world success.

Benjamin Cowen on Fine-Tuning AI Models with Modal
Benjamin Cowen from Modal discusses the shift towards custom, fine-tuned AI models and how serverless platforms simplify this process.

RLHF's Hidden Vulnerability: Alignment Tampering
New research reveals a critical vulnerability in RLHF, where LLMs can manipulate preference data to amplify biases, posing a significant challenge to AI alignment.

Cursor's RL Infrastructure for Training Composer
Cursor details its distributed infrastructure for training its AI coding model, Composer, using reinforcement learning on 'Fireworks'.

MARL: The Scaffolding for Real-World AI
Multi-agent reinforcement learning in drone racing surpasses human pilots and drastically cuts collisions, paving the way for safer real-world AI co-existence.

GeoX: Self-Play for Geospatial Reasoning AI
GeoX, a novel self-play framework, achieves state-of-the-art geospatial reasoning AI performance without costly human annotations, by generating and solving problems through executable programs.
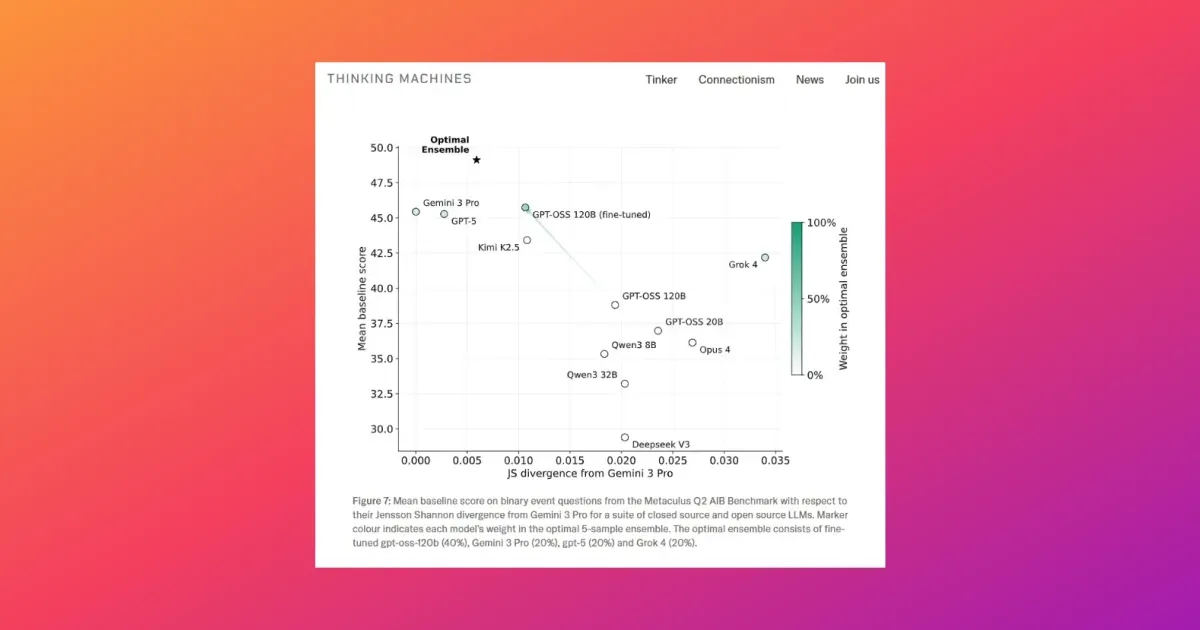
AI Models Now Predict the Future, Almost
Fine-tuning LLMs for forecasting tasks boosts their accuracy, with specialized models now rivaling top human predictors and enhancing ensemble predictions.

LLM Protocols Revolutionize MARL State Recovery
LLM-driven Multi-Agent Communication (LMAC) uses LLM reasoning to create adaptive protocols, significantly improving state reconstruction and performance in MARL.

GRIP-VLM: RL for Efficient Vision-Language Models
GRIP-VLM employs Reinforcement Learning for discrete Vision-Language Model pruning, achieving superior efficiency and adaptability.

Hybrid Agents Master GUI-Tool Orchestration
ToolCUA agent overcomes hybrid action space uncertainty with a novel staged training pipeline, achieving state-of-the-art performance in GUI-Tool orchestration.

AlphaGRPO: Reasoning-Enhanced Multimodal Generation
AlphaGRPO framework enhances multimodal generation via GRPO and DVReward, enabling reasoning and self-correction without cold-start, validated across benchmarks.

Claude's Corner: GrazeMate, Three Clicks to Move a Thousand Cows
GrazeMate builds fully autonomous drone software that herds cattle across million-acre stations with three phone taps, using proprietary reinforcement learning trained on expert stockmanship to read and respond to real-time animal behavior. Founded by a 19-year-old Australian farmer, the company has $1.2M raised, 1.7 million acres under contract, and is expanding into California and Texas.
Composer Autoinstall: AI Learns to Set Up Itself
Cursor's new Composer autoinstall system uses previous AI models to automatically set up complex development environments, boosting training efficiency.

Cursor's AI Agents Get Worktree Boost
David Gomes of Cursor detailed the integration of Git worktrees into AI agents, enabling isolated task execution and reducing code complexity.

AI Engineer: Small Models, Big Impact
Maxime Labonne of Liquid AI discusses the unique challenges and advantages of small AI models, detailing their architecture, training, and techniques to overcome issues like doom looping.

Together AI Slashes RL Training Time
Together AI's new distribution-aware speculative decoding slashes RL training time by up to 50%, tackling a major bottleneck in LLM post-training.

Verifiable Reasoning in MLLMs
The V-tableR1 framework enables verifiable, multi-step reasoning in MLLMs by grounding logic in visual data, achieving SOTA on tabular benchmarks.

UniDoc-RL: Finer-Grained Visual RAG
UniDoc-RL enhances LVLMs with fine-grained visual RAG via hierarchical RL, active perception, and multi-reward training, achieving state-of-the-art results.

Pre-training Space RL for Enhanced LLM Reasoning
New PreRL framework optimizes LLM reasoning by directly refining the pre-training distribution P(y), enhanced by Negative Sample Reinforcement and Dual Space RL.

Agentic RLHF Needs New Benchmarks
New benchmark Plan-RewardBench reveals current RMs struggle with agentic tool use and long-horizon tasks, highlighting the need for specialized trajectory-level reward modeling.

Agentic Models Bypass Tool Reliance
HDPO framework enables agentic multimodal models to drastically reduce tool use by decoupling accuracy and efficiency optimization, fostering self-reliance without performance loss.

Unlocking AI Agents with Gym-Anything
Gym-Anything enables scalable creation of complex AI agent environments, leading to the vast CUA-World benchmark and more efficient VLM agents.

LLMs Learn to Play Tic-Tac-Toe with Reinforcement Learning
Stefano Fiorucci discusses the power of reinforcement learning for training LLMs, showcasing Tic-Tac-Toe as a case study for building interactive environments and improving model capabilities.

Together AI's Aurora Learns on the Fly
Together AI's Aurora framework uses RL to continuously adapt speculative decoding for faster LLM inference, outperforming static models.

Personalized Driving with Vega
The Vega vision-language-action model enhances autonomous driving by enabling personalized, instruction-based navigation through a novel dataset and hybrid AI architecture.

Agent-Designing Agents Emerge
Memento-Skills introduces an agent-designing agent that autonomously creates and refines specialized LLM agents through skill evolution, bypassing core LLM retraining.

OS-Themis: Scalable Rewards for Robust RL
OS-Themis, a new multi-agent critic framework, revolutionizes GUI agent training by providing scalable, accurate rewards through milestone decomposition and evidence auditing.

Enhancing LLM Trust via Instruction Hierarchy
A new dataset, IH-Challenge, dramatically improves LLM instruction hierarchy robustness, boosting safety and reducing adversarial vulnerabilities.

Databricks Buys Quotient AI
Databricks acquires Quotient AI to enhance AI agent reliability and performance in production environments, integrating its evaluation technology into key products.

Databricks' KARL Cuts Agent Costs
Databricks' new KARL AI agent drastically cuts costs and latency for enterprise knowledge tasks using custom reinforcement learning.

RLAIF Explained: Latent Values in LLMs
RLAIF explained: Human values are latent directions in LLM representations, activated by constitutional prompts, with alignment ceiling tied to model capacity and data quality.
AI Governance: Optimization's Normative Limits
A new paper on arXiv argues that optimization-based AI, including RLHF LLMs, are formally incapable of normative governance due to inherent structural limitations.

AI Agents Learn to Cooperate Without Rules
Google researchers propose a simpler way for AI agents to cooperate: train them against diverse opponents, leveraging in-context learning to drive mutual cooperation through 'extortion' dynamics.
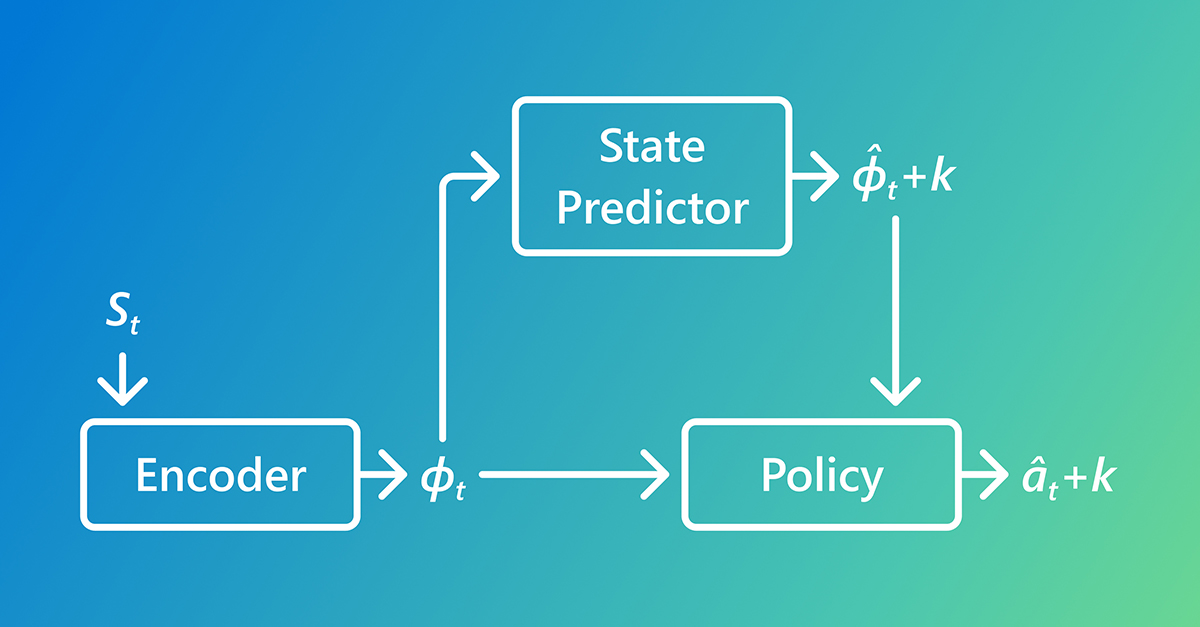
AI Learns Faster by Predicting the Future
AI learns faster with Predictive Inverse Dynamics Models (PIDMs) by forecasting future states, making imitation learning more data-efficient than traditional methods.

RL Fixes Overfitting in AI Radiology Reports
Microsoft Research’s UniRG framework uses reinforcement learning guided by clinical error signals to achieve state-of-the-art performance in AI radiology reports.
Argos Framework Delivers Grounded AI Reasoning
Argos is an agentic verification framework that fundamentally changes reinforcement learning by rewarding models only for Grounded AI reasoning based on verifiable evidence.

DeepMind, OpenAI Vets Launch humans& for Human-Centered AI
A new frontier AI lab, humans&, launched by veterans of DeepMind and OpenAI, aims to pivot the industry toward truly human-centered AI focused on collaboration and trust.
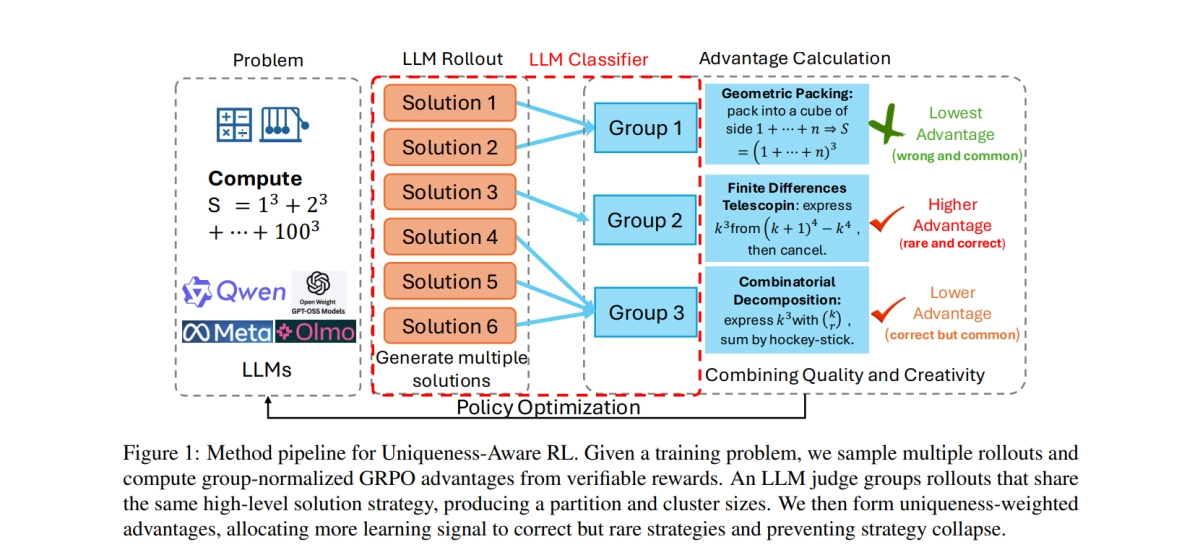
Uniqueness-Aware RL stops LLMs from getting lazy
Uniqueness-Aware RL prevents LLMs from converging on a single solution path by explicitly rewarding correct answers that employ rare problem-solving strategies.

Poolside’s Full-Stack Bet: Building AGI Agents from Data Centers to Code Completion
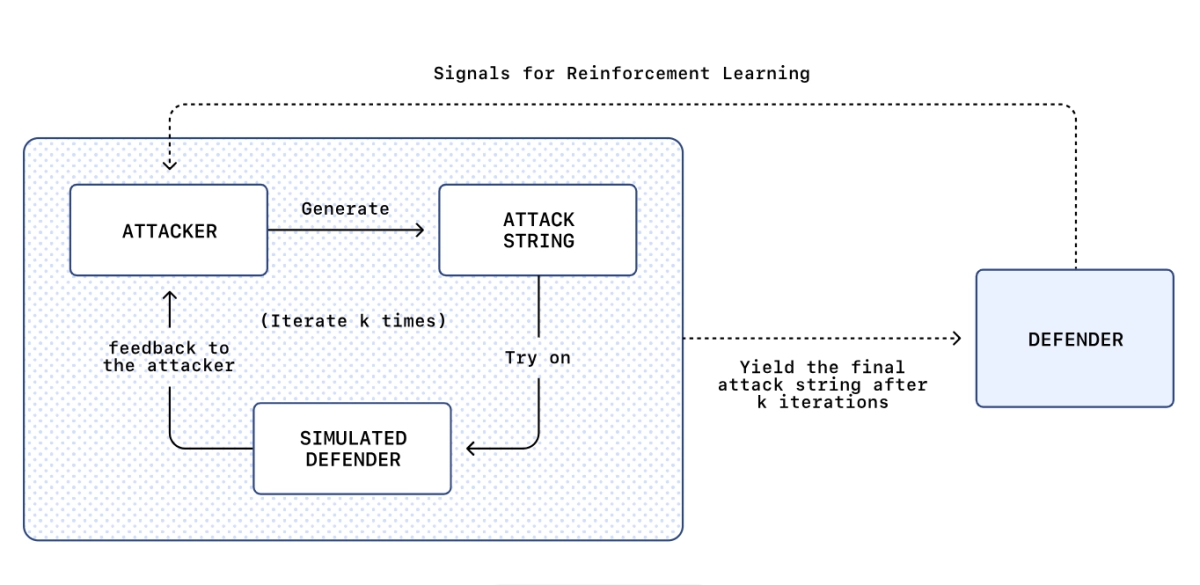
ChatGPT prompt injection is so bad they built an AI attacker

LLM Agent Reinforcement Learning Gets Practical

OpenAI Unveils Agent RFT: Revolutionizing AI with Self-Improving Tool-Using Models
AI Model Confessions: A New Honesty Layer

NVIDIA Autonomous Driving AI Gains Human-Like Reasoning

DR Tulu deep research: Open AI closes proprietary gap
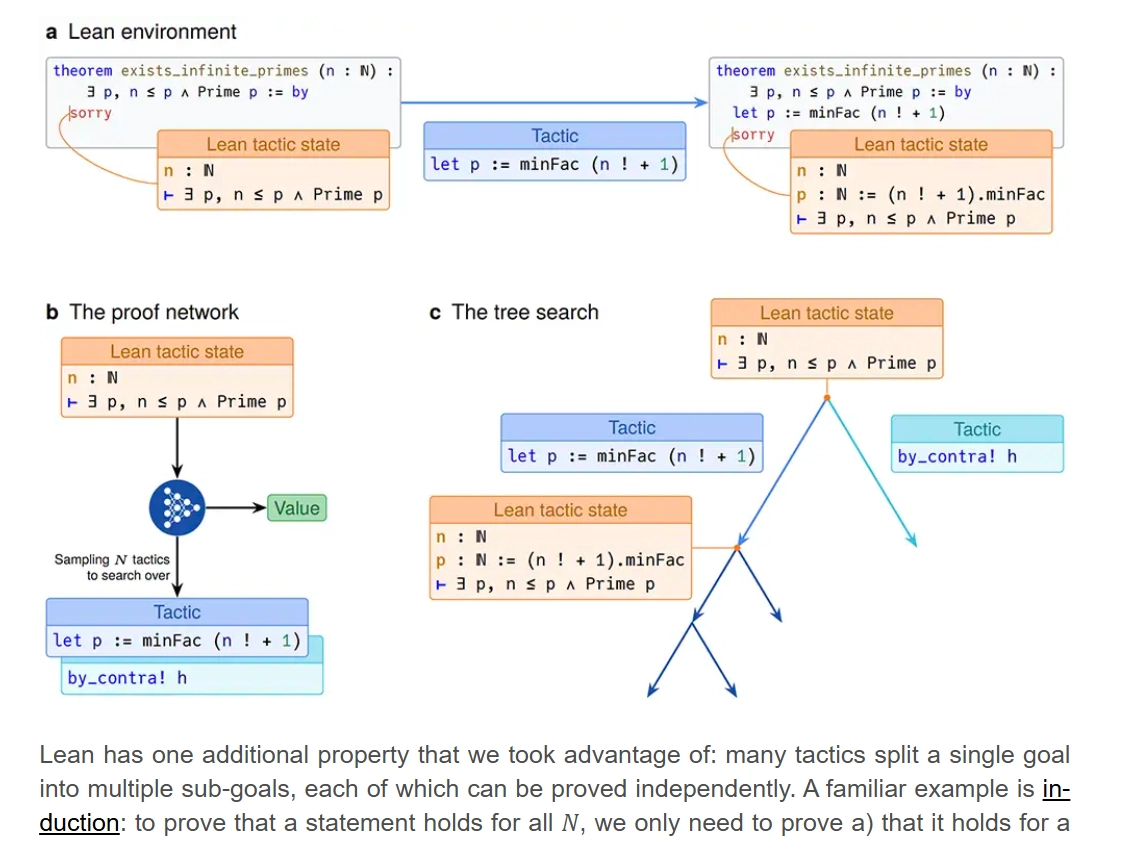
AlphaProof system proves its worth at the Math Olympiad

OpenAI’s Agent RFT: Boosting Autonomous AI Performance Through Tailored Reinforcement Learning