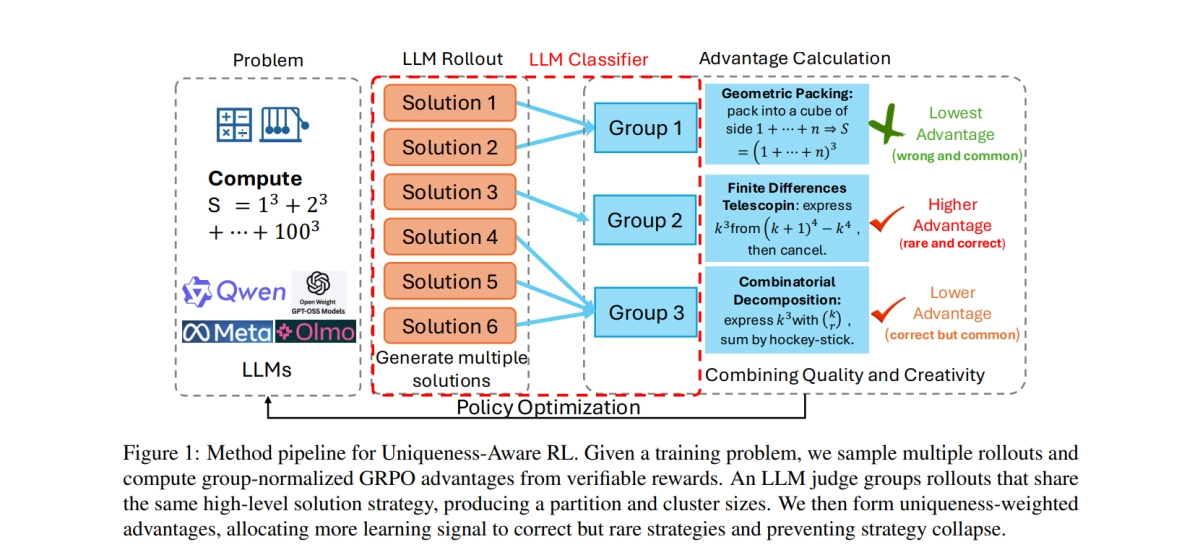
Reinforcement learning (RL) is the engine powering the next generation of large language models, from DeepSeek-R1 to the rumored GPT-5. It is the primary method used to refine an LLM’s complex reasoning skills after pretraining. But RL has a fundamental, inherited flaw that is now hitting the ceiling of LLM performance: exploration collapse.
When training an LLM on complex tasks like math or physics, the policy quickly finds one reliable way to solve the problem, say, using the quadratic formula, and then stops exploring alternative, potentially more elegant or robust strategies, like factoring. This premature convergence, known as policy collapse, means models get better at finding *one* correct answer (improving pass@1) but fail to maintain strategic diversity, limiting their ability to solve problems when multiple attempts are needed (pass@k).