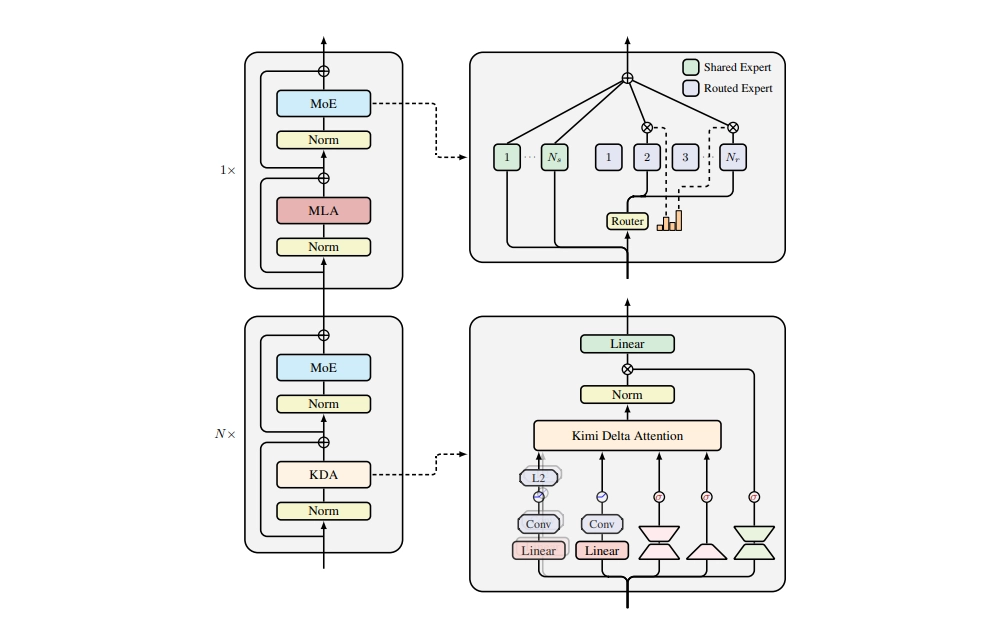
Moonshot AI has released Kimi Linear, a new large language model built on a hybrid attention architecture that it claims is both more efficient and more powerful than traditional transformer models. The open-source release, detailed in a new technical report, is already stirring debate in the AI community about its performance and practicality.
At its core, Kimi Linear uses a mix of attention mechanisms. For every three layers of its novel Kimi Delta Attention (KDA), a type of efficient linear attention, it includes one layer of standard Multi-Head Latent Attention (MLA). This 3:1 hybrid design, according to the Kimi Team, is the key to its success. The company reports that Kimi Linear outperforms comparable full-attention models across short-context, long-context, and reinforcement learning tasks, all while cutting KV cache usage by up to 75% and boosting decoding throughput by up to 6x for million-token contexts.