Updating the brains of a massive AI model used to be a sluggish affair, often taking minutes to sync new knowledge from a training cluster to a live inference cluster. Now, a new technique for fast GPU weight transfer has slashed that time to a mere 1.3 seconds for a trillion-parameter model, a critical breakthrough for real-time reinforcement learning (RL).
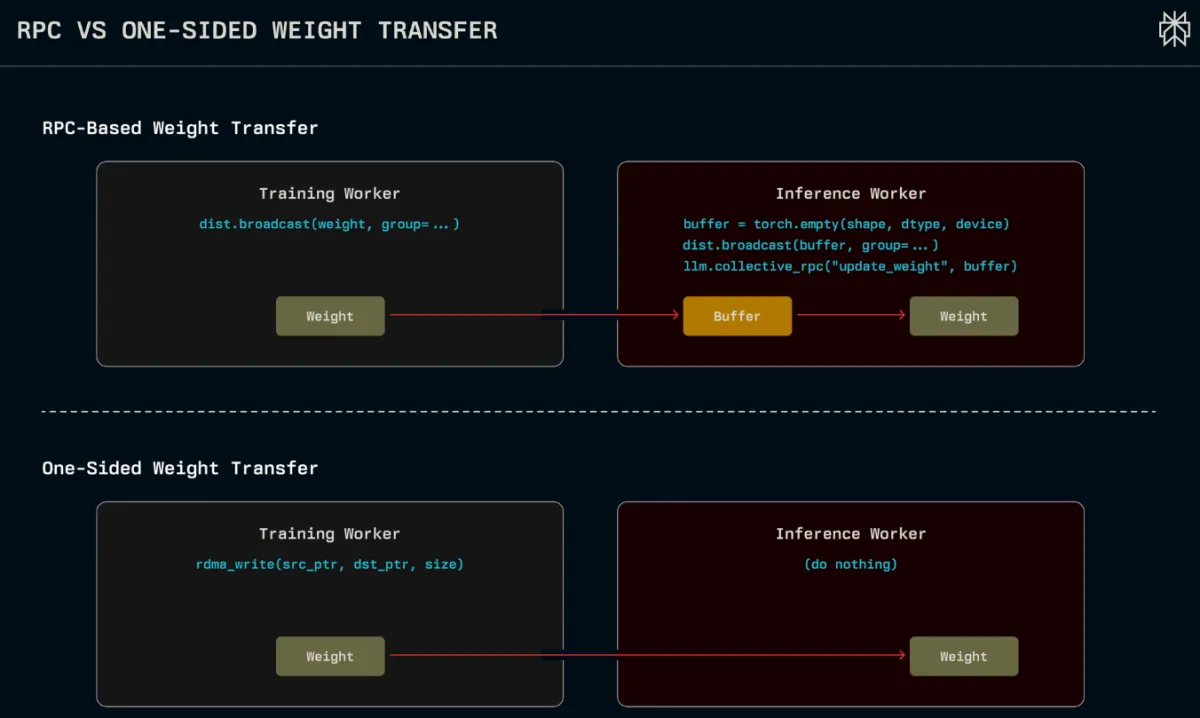
The achievement, detailed by the engineering team behind the Kimi-K2 model, addresses a fundamental bottleneck in modern AI. In asynchronous RL, models are constantly learning on one set of GPUs while serving users on another. The delay in transferring these learned "weights" means the inference model is always working with stale information. Existing frameworks that funnel all data through a single GPU create a traffic jam, limited by one machine's bandwidth.