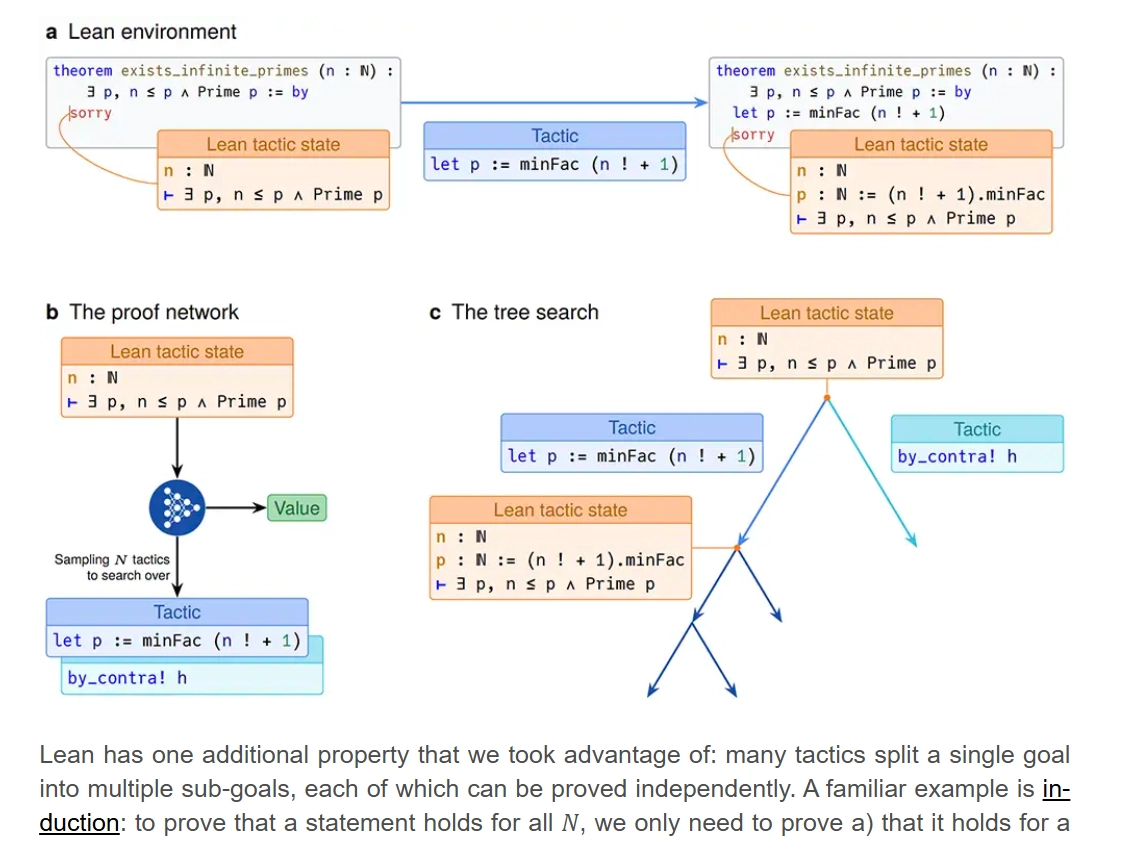
The quest to build an AI capable of advanced mathematical reasoning has hit a major milestone. Researchers behind the new AlphaProof system, detailed in a paper published in Nature, have demonstrated an AI capable of solving problems from the notoriously difficult International Mathematical Olympiad (IMO), achieving a silver medal performance in the 2024 contest.
The AlphaProof system, developed by Julian Schrittwieser and colleagues while at Google DeepMind, successfully generated formal proofs for three of the six IMO problems (P1, P2, and P6). Crucially, P6 was considered the hardest problem of the contest, solved by only five out of 609 human participants. This achievement isn't just about solving hard math; it’s about solving it with guaranteed, verifiable truth, bypassing the hallucination issues plaguing general-purpose large language models (LLMs).