Teaching AI agents to perform tasks by showing them human examples, a process known as imitation learning, typically relies on mapping current observations directly to actions. This common method, Behavior Cloning (BC), often requires vast datasets to account for human variability, a significant hurdle in real-world applications. A new approach, Predictive Inverse Dynamics Models (PIDMs), detailed in research from Microsoft Research, offers a more data-efficient path by fundamentally rethinking how AI learns from demonstrations.
Rethinking Imitation Learning
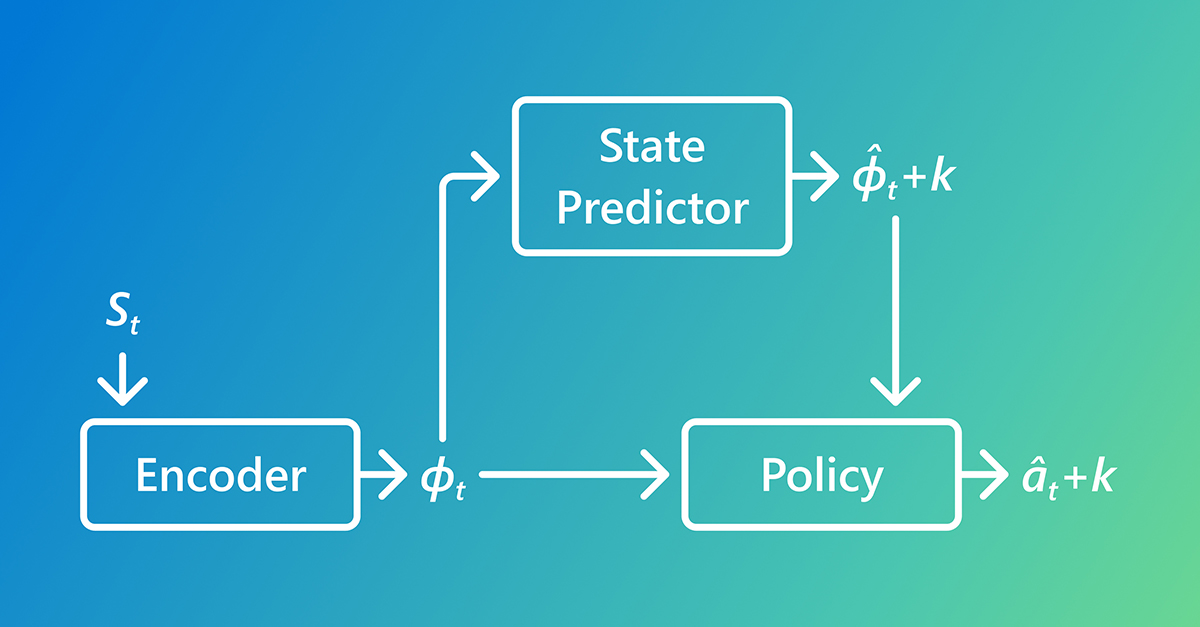
Instead of a direct state-to-action mapping, PIDMs break down imitation learning into two distinct stages. First, they employ a state predictor to forecast plausible future states. Second, an inverse dynamics model uses this predicted future state to infer the action required to transition from the current state towards that predicted future. This two-stage process reframes the core question from 'What action would an expert take?' to 'What is the expert trying to achieve, and what action leads there?'