The rise of AI agents that operate inside your browser has created a terrifying new security paradigm. When ChatGPT Atlas is given the keys to your emails, documents, and banking sites, it becomes a high-value target for manipulation. The most significant threat? **ChatGPT prompt injection**, where malicious instructions are hidden inside content the agent processes, hijacking its behavior.
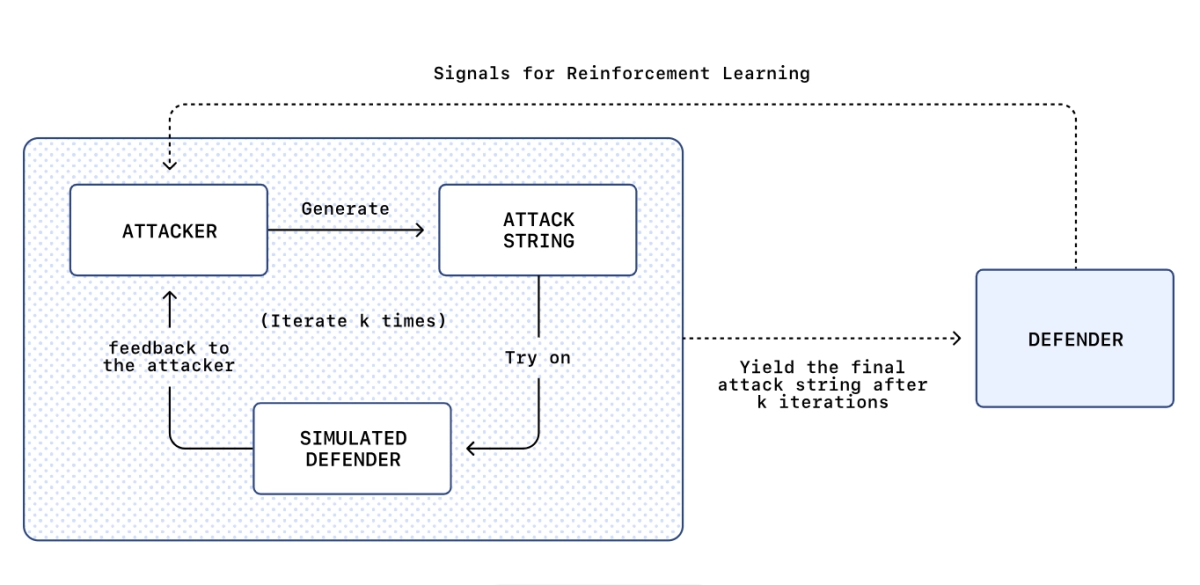
In a candid disclosure, the team behind ChatGPT Atlas revealed they are now fighting fire with fire, deploying an automated, reinforcement learning (RL) powered attacker to hunt for exploits that human red teamers simply cannot find.