#Computer Vision
50 articles with this tag

WCog-VLA: Bridging Foresight for Proactive Autonomy
WCog-VLA pioneers a dual-level framework, unifying semantic forecasting with generative world evolution to enable proactive autonomous driving, achieving SOTA on NAVSIM.

State of the Union: Local AI Focus
Nvidia, Osmantic, Roboflow, and EXO Labs discuss the critical shift towards local AI solutions and its implications.

CARLA-GS: Unified Corner-Case Synthesis
CARLA-GS offers a unified, modular pipeline for synthesizing photorealistic and physically consistent corner cases in autonomous driving simulation.

ELSA3D: Structured Text-3D Reasoning
ELSA3D revolutionizes unified 3D models with elastic semantic anchoring, achieving SOTA performance in 3D generation and captioning while halving computational costs.

AI Learns to Smell: The Science of Olfactory AI
AI is learning to smell thanks to companies like Osmo, which are building models to understand, predict, and design scents by mapping molecular structures to olfactory perception.

CamVLA: Unshackling Robot Control from Camera Calibration
CamVLA revolutionizes robot control by enabling policies to infer camera geometry, achieving robust, calibration-free manipulation from single RGB images.

VisionAId: On-Device Vision for the Visually Impaired
VisionAId transforms smartphones into real-time visual assistants for the visually impaired, leveraging on-device AI and few-shot learning for personalized object recognition and multimodal guidance.

Netflix Tackles AI Video Editing Challenges
Netflix is developing advanced AI tools, Vera and VOID, to enhance video editing precision and realism for creators.

How Adult Websites Use AI: Inside Pornhub's Tech Stack and the Porn AI Boom
How do adult websites use AI? A technical deep dive into the Pornhub AI stack: computer vision tagging, recommendation pipelines, content moderation, and neural upscaling that power modern adult tech.

OneCanvas: Unified 3D Scene Representation
OneCanvas revolutionizes 3D scene understanding in VLMs by projecting multi-view features onto a unified equirectangular canvas, enabling efficient situated reasoning and SOTA performance.

Phase Dominance in AI Image Recognition
AI image classifiers exhibit a striking phase dominance for identity encoding, mirroring human vision principles, with architectural differences shaping its expression.

ActiveSAM: Efficient Open-Vocabulary Segmentation
ActiveSAM revolutionizes open-vocabulary semantic segmentation with a training-free framework that dynamically identifies relevant classes, boosting speed and accuracy while enhancing robustness for real-world AI.

HYDRA-X: Unifying Image & Video Tokenization
HYDRA-X, a novel Vision Transformer-based UMM, unifies image and video tokenization, enhancing editing consistency and performance through causal attention and latent-level manipulation.

Humanoids Learn Self-Other Distinction
Humanoid robots now learn self-other distinction and build predictive self-models from sensory data, enabling better collaboration and task performance in human-robot environments.

Rethinking VLM Token Reduction
Reroute transforms VLM token reduction from irreversible pruning to recoverable routing, improving grounding performance without sacrificing efficiency.

Images as the New Reasoning Medium
This paper introduces optical reasoning, enabling images to serve as the primary medium for LLM and MLLM reasoning, achieving higher token efficiency and competitive performance.

Beyond Observable Data: Imaginative Perception for VLMs
Researchers introduce Imaginative Perception Tokens (IPTs) to enable VLMs to reason about unobserved spatial configurations, outperforming textual chain-of-thought.

Fei-Fei Li Clarifies 'World Models'
Fei-Fei Li offers a framework to define AI 'world models', distinguishing them from language models and tracing their roots to agent-environment interaction.

AdaCodec: Efficient Video MLLM Encoding
AdaCodec revolutionizes video MLLMs by using predictive visual coding to drastically cut tokenization costs and latency, achieving superior performance at a fraction of the budget.

GPIC: Fueling Next-Gen Generative Models
The GPIC dataset, a 28 trillion pixel permissive image corpus, democratizes large-scale visual generative model research and commercialization.

LocateAnything: Parallel Decoding for Vision
LocateAnything revolutionizes vision-language models with Parallel Box Decoding, boosting speed and accuracy in visual grounding and detection.
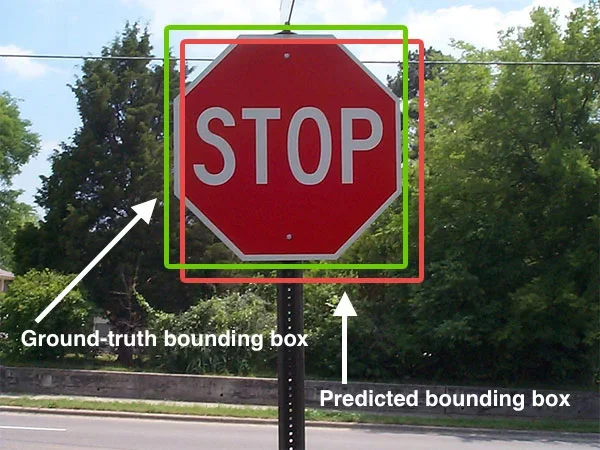
Uber Fights Bounding Box Errors
Uber Engineering uses machine learning to automatically detect and correct bounding box annotation errors in video data, boosting ML model training quality.

AI Image Generation Reimagined: Channel-Wise Quantization
Channel-wise Vector Quantization (CVQ) redefines image tokenization, enabling autoregressive models like CAR to generate richer, more detailed images with state-of-the-art performance.

SpatioRoute VLM: Dynamic Prompting for Video QA
SpatioRoute VLM revolutionizes zero-shot spatial video question answering with dynamic prompt routing, achieving SOTA without fine-tuning or 3D sensors.

TaskGround: Bridging Scene Context and Action
TaskGround revolutionizes household AI by enabling compact models to interpret complex scenes, infer task structures, and act effectively, drastically improving performance and reducing costs.

AI Learns to See, Hear, and Understand
Multimodal AI analytics is enabling businesses to decode video, audio, and images, unlocking deeper insights from previously unstructured data.

LMPath: Semantics Supercharge UAV Search
LMPath integrates language and vision models to create semantically-aware exploration priors for UAVs, dramatically improving search mission efficiency over traditional geometric methods.

Beyond RGB: Grounding Vision-Language on Raw Sensor Data
PRISM-VL advances vision-language models by grounding them in raw camera measurements, not just RGB, significantly improving performance on challenging visual tasks.

Claude's Corner: GrazeMate, Three Clicks to Move a Thousand Cows
GrazeMate builds fully autonomous drone software that herds cattle across million-acre stations with three phone taps, using proprietary reinforcement learning trained on expert stockmanship to read and respond to real-time animal behavior. Founded by a 19-year-old Australian farmer, the company has $1.2M raised, 1.7 million acres under contract, and is expanding into California and Texas.

Codex AI Automates Complex Computer Tasks
Codex AI demonstrates advanced capabilities, automating complex tasks across applications by interacting with computer interfaces.
Claude's Corner: Librar Labs, The AI Librarian That's Really a Data-Catalog Trojan Horse
Librar Labs looks like another YC W2026 SaaS, AI-powered school library management, until you look at the team and the technical claim under the hood. OpenAI / Scale / Palantir alums plus quantum physicists plus a 'self-healing database for unstructured data' don't build a school librarian assistant unless the school librarian is the wedge.

MLX Genmedia: Prince Canuma on On-Device AI
Prince Canuma of MLX Genmedia discusses the power of on-device AI, showcasing how MLX enables efficient deployment of AI models on Apple Silicon devices for vision and audio tasks.

Transformers Conquer Computer Vision
Isaac Robinson from Roboflow explains how Transformers, once confined to NLP, have revolutionized computer vision, surpassing CNNs through massive pre-training and architectural innovation.

Black Forest Labs: FLUX and the Future of Visual AI
Stephen Batifol of Black Forest Labs discusses FLUX, the company's visual AI model, and the future of generative AI with a focus on real-time generation and world models.

PhyCo: Bridging Physics and Video Generation
PhyCo introduces a framework for physically consistent and controllable video generation, overcoming limitations of current diffusion models through physics-supervised fine-tuning and VLM-guided rewards.

X-WAM: Bridging Action and 4D Synthesis
The X-WAM unified 4D world model revolutionizes robotics by integrating real-time action with high-fidelity 4D synthesis, achieving state-of-the-art benchmarks.

Mosaic SoC raises $3.8M for spatial intelligence chips
Mosaic SoC raises $3.8M for chips that bring real-time spatial intelligence to devices, enabling advanced perception with minimal power consumption.

UniDoc-RL: Finer-Grained Visual RAG
UniDoc-RL enhances LVLMs with fine-grained visual RAG via hierarchical RL, active perception, and multi-reward training, achieving state-of-the-art results.

RadAgent: Interpretable AI for Medical Imaging
RadAgent offers interpretable, agent-based CT report generation, significantly improving accuracy, robustness, and introducing crucial faithfulness.

Beyond Black-Box: Structuring Humor AI Reasoning
New IRS framework moves beyond black-box AI, structuring humor understanding via explicit incongruity-resolution reasoning for expert-level performance.

Anthropic Unveils Updated AI Model Opus 4.7
AI research company Anthropic has released an updated version of its AI model, Opus 4.7, boasting enhanced computer vision capabilities and a continued focus on safety.

HiVLA: Decoupling Reasoning for Robotic Control
HiVLA decouples VLM reasoning from motor control using a hierarchical framework, enhancing robotic manipulation performance and preserving zero-shot capabilities.

Adaptive Zooming for Precise GUI Grounding
UI-Zoomer revolutionizes GUI grounding with a training-free adaptive zoom-in approach, enhancing localization accuracy by intelligently quantifying and responding to prediction uncertainty.

Anthropic Unveils Opus 4.7: A Leap in AI Coding and Vision
Anthropic unveils its updated Opus 4.7 AI model, boasting enhanced coding and computer vision capabilities, with a key focus on cybersecurity.

Bridging Vision Tools and LLMs with P2
Perception Programs (P2) transforms raw vision tool outputs into structured summaries, dramatically enhancing MLLM reasoning without retraining.

Automating High-Quality Image Editing Data
A new pipeline, EditCaption, drastically improves VLM instruction synthesis for image editing, boosting Qwen3-VL performance and reducing critical errors.

Instance-Aware VLP: Beyond Global Understanding
InstAP introduces instance-aware pre-training for VLP, enhancing instance-level reasoning and global understanding with the InstVL dataset.

MoRight: Causal Control in Video Generation
MoRight revolutionizes video generation by enabling disentangled motion control and modeling motion causality for realistic, interactive scene dynamics.

IBM Master Inventor Explains Multimodal AI
IBM Master Inventor Martin Keen explains the evolution of multimodal AI, contrasting feature-level fusion with native multimodality and the importance of temporal reasoning for video.

EdgeDiT: Transformers on the Edge
EdgeDiT brings high-fidelity generative AI to mobile devices by optimizing Diffusion Transformers for NPUs, achieving significant efficiency gains.