#Multimodal AI
50 articles with this tag

Mistral AI's Vox-Trainer and Fine-Tuning
Mistral AI announces Vox-Trainer, a new multimodal AI model for voice cloning and speech generation, alongside new benchmarks for speech understanding.

3D Grounding for Vision-Language Models
Loc3R-VLM enhances 2D VLMs with 3D spatial reasoning from monocular video, achieving SOTA in language-based localization and 3D QA.

PRIMO R1: Active Critics for Robotic Manipulation
PRIMO R1 transforms video MLLMs into active critics for robotic manipulation via outcome-based RL, achieving SOTA on RoboFail and outperforming larger models.

Mistral Small 4 Unifies AI Capabilities
Mistral AI unveils Mistral Small 4, a unified model combining text, image, reasoning, and coding capabilities under an open-source license.

CoCo: Code Drives Precise Image Generation
CoCo leverages executable code for precise, structured text-to-image generation, outperforming existing methods on complex benchmarks.

Code-Driven Reasoning for Precise Image Generation
CoCo (Code-as-CoT) introduces executable code as a reasoning framework for text-to-image generation, achieving superior precision and control.

AI Learns Beyond Text
AI is moving beyond text, with multimodal pretraining enabling models to learn from images, audio, and video for richer comprehension.
Microsoft's Compact AI Learns to Reason
Microsoft's new Phi-4-reasoning-vision-15B model offers strong multimodal reasoning capabilities in a compact, efficient package.

Crab+ Unifies AV-LLMs, Reverses Negative Transfer
Crab+ introduces a novel approach to Audio-Visual Large Language Models, overcoming negative transfer via explicit cooperation in data and model design.
Microsoft's Phi-4-reasoning-vision-15B compact AI model
Microsoft Research's Phi-4-reasoning-vision-15B offers efficient multimodal AI, excelling in reasoning and vision tasks with less data and compute.
Google's Interactions API Evolves Gemini
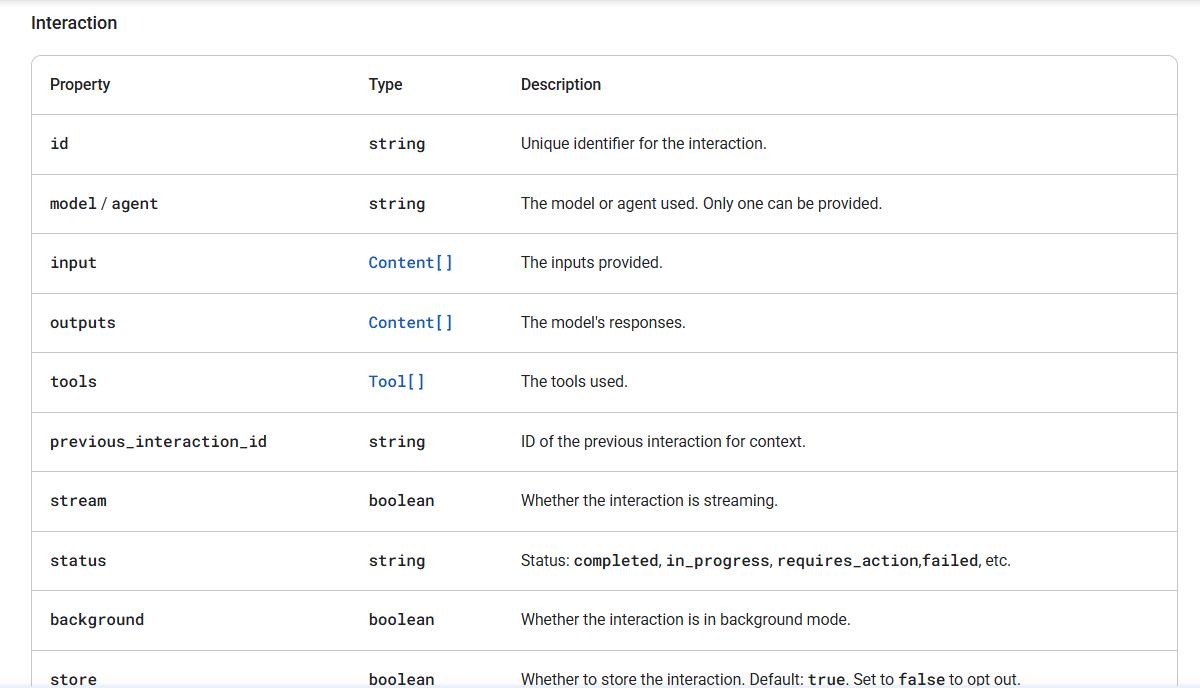
Google's new Interactions API for Gemini models offers a unified interface for complex AI tasks, supporting multimodal inputs, agents, and tool integration.
Multimodal LLMs: What's Lost in Translation?
New research reveals multimodal LLMs struggle to utilize non-textual data due to a 'mismatched decoder problem,' impacting their true understanding.
Less Data, More Alignment: SOTAlign
Researchers introduce SOTAlign, a framework that achieves robust cross-modal alignment using significantly less paired data by leveraging unpaired samples.

Agentic Vision Gemini 3 Flash: Code Execution Solves Visual Hallucination
Agentic Vision Gemini 3 Flash shifts multimodal AI from static image processing to an active, code-driven investigation, dramatically improving accuracy and verifiability.

Sparkli AI raises $5M to kill the EdTech chatbot for kids
Sparkli AI, founded by Google alums, raised a $5 million pre-seed round to develop a multimodal, simulation-based learning engine for children aged 5 to 12.
Argos Framework Delivers Grounded AI Reasoning
Argos is an agentic verification framework that fundamentally changes reinforcement learning by rewarding models only for Grounded AI reasoning based on verifiable evidence.

Gemini API Data Ingestion Gets Production Ready
Google has upgraded Gemini API data ingestion to support persistent storage via GCS registration and external signed URLs, boosting the inline limit to 100MB.

The AI Pet Startup That Claims to Translate Your Dog's Thoughts
Google Gemini 3 Redefines AI Reasoning and Efficiency

Google AI Tips: A Year of Ubiquitous Intelligence

T5Gemma 2 Multimodal Ushers In Efficient AI Future
Tinker launches OpenAI API compatibility, challenging vendor lock-in.
Gemini Google Translate Elevates Nuance

Gemma 3n Powers Real-World Impact at the Edge
FACTS Benchmark Suite Elevates LLM Factuality Scrutiny

AI Precision Oncology Gets Scalable Boost from Microsoft AI

Google's Gemini 3 Ushers In The Latest AI Era

VoiceVision RAG: Beyond Text, Towards True Multimodal Document Intelligence

Google TAU AI Partnership Expands Foundational AI Research

Google Cloud's Nano Banana Transforms Text-to-Vision Capabilities

Gemini 3 Unleashes a New Era of AI-Powered Creation
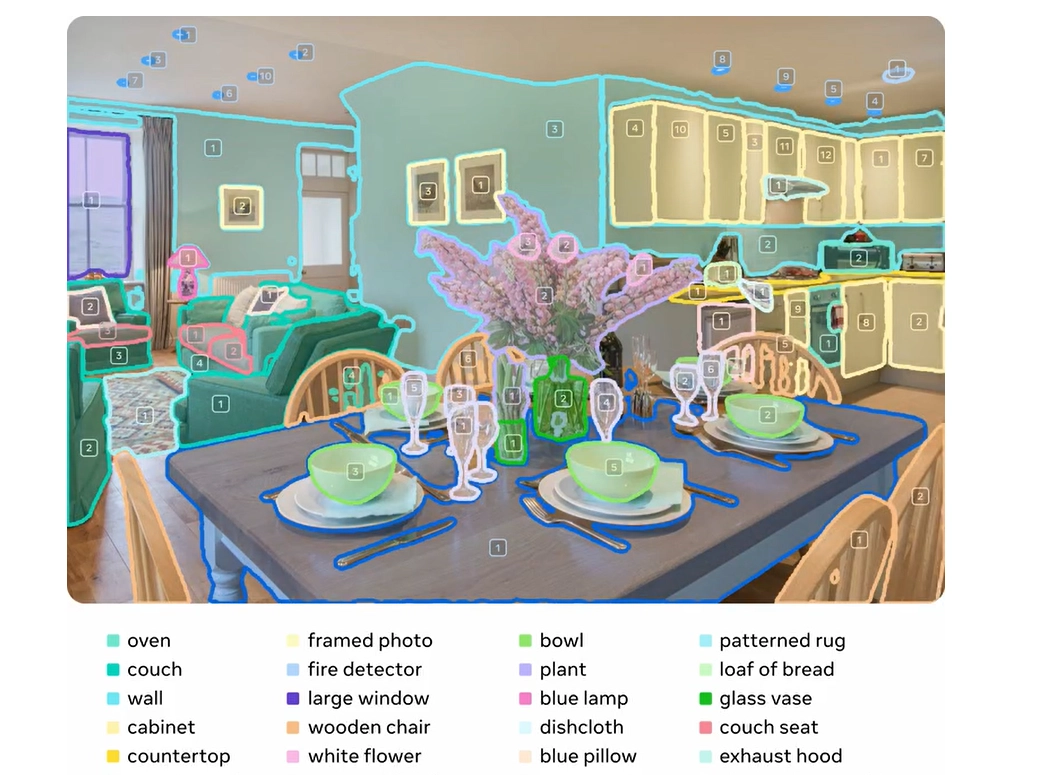
Meta’s Segment Anything Model 3 masters text and video
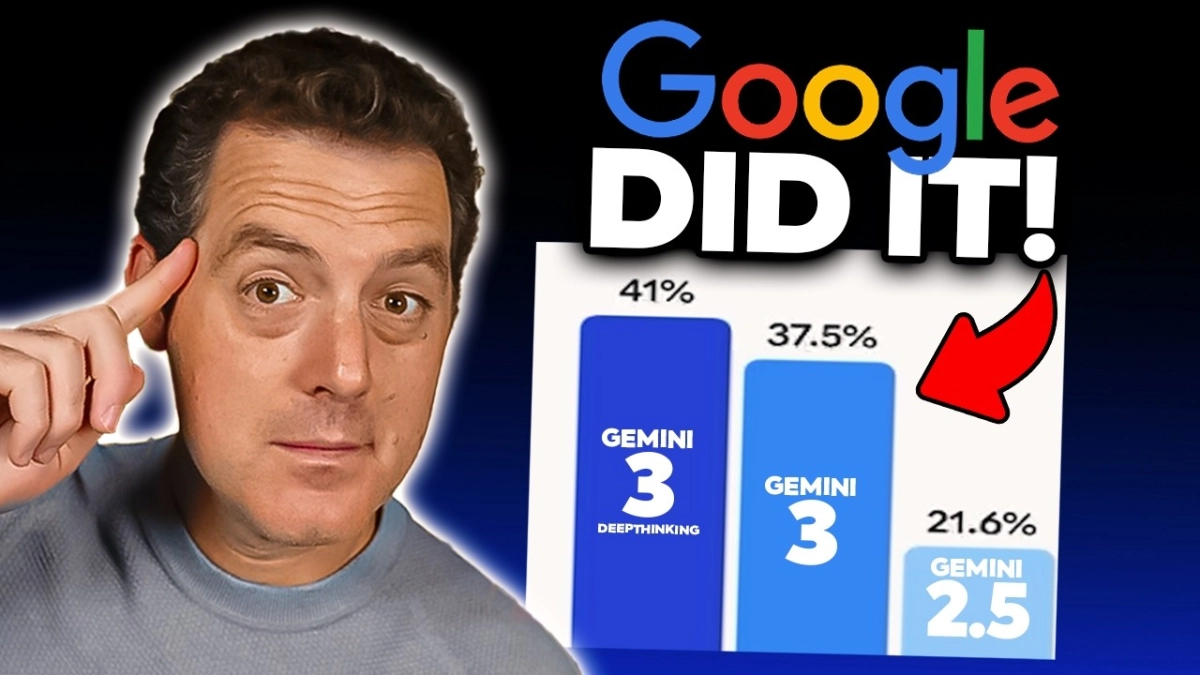
Gemini 3: Google's Ambitious Leap Towards Universal AI Integration

Google Gemini 3 Elevates AI with Agentic Interfaces

NotebookLM Deep Research Redefines AI Analysis

Marble World Model Goes Public, Redefining 3D Generation

MMCTAgent: Microsoft's Multimodal Reasoning Agent Tackles Long-Form Video

Google's Nano Banana: The Human-Centric Evolution of Visual AI

Emotive AI Redefines Customer Experience Dynamics

Signify Elevates Support with Advanced Retrieval Augmented Generation
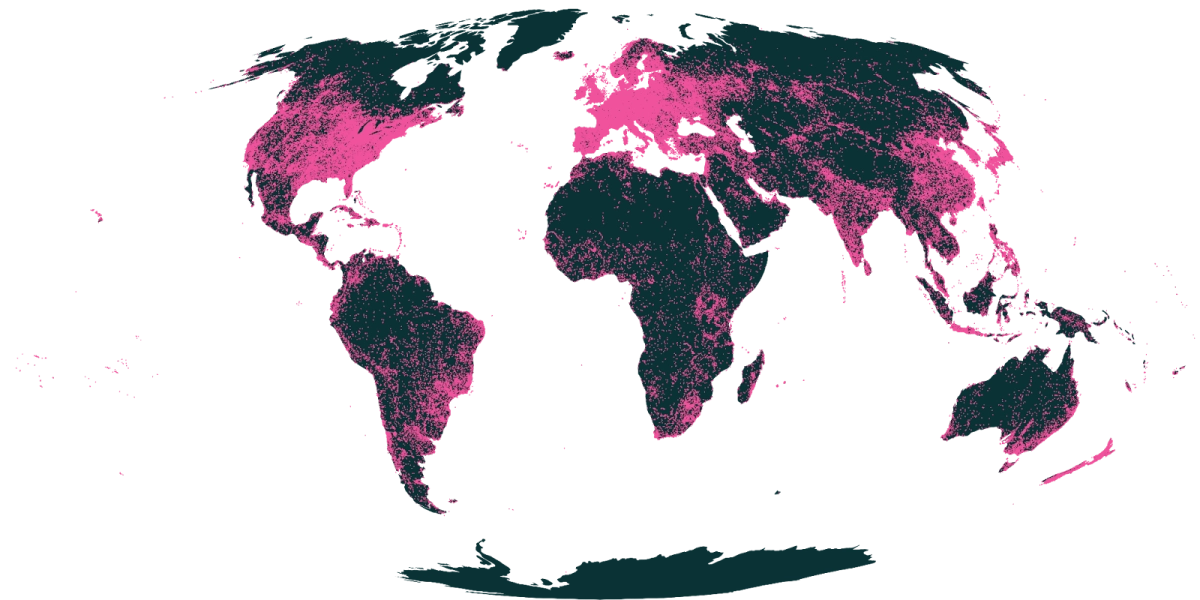
OlmoEarth Redefines Earth Observation Foundation Models

OpenAI's Patent Strategy: Why the AI Leader Has Far Fewer Patents Than You'd Expect

Automotive AI: Redefining Vehicle Design Quietly
Artificial intelligence is fundamentally reshaping vehicle design, moving beyond the long-promised fully autonomous car to deliver immediate, tangible improvements in today's vehicles. This evolution, often subtle, is driven by a sophisticated blend of on-device intelligence...
Fal.ai raises funding to advance multimodal AI platform
\n Multimodal AI startup Fal.ai has raised new funding, estimated at $250 million. This investment values the company at more than $4 billion.
Fal.ai raises funding to advance multimodal AI platform
\n Multimodal AI startup Fal.ai has raised new funding, estimated at $250 million. This investment values the company at more than $4 billion.

Nano Banana AI Elevates NotebookLM Video Overviews
Gemini 2.5 Pro Transforms Video Processing with Single API Calls
Ayo Adedeji, Google\'s Developer Relations Engineer, boldly declared, \"Or, you could just not do any of that.

Gemini 2.5 Pro Transforms Video Processing with Single API Calls
Ayo Adedeji, Google\'s Developer Relations Engineer, boldly declared, \"Or, you could just not do any of that.
Google AI Plus Expands to 40 New Countries, Shaking Up the AI Race
