#Multimodal AI
50 articles with this tag

Open Source AI Beats Proprietary on Cost, Quality
Open-source AI models like Kimi K2.7 Code are proving to be cost-effective and quality-competitive alternatives to proprietary AI, especially with multimodal inputs.

HYDRA-X: Unifying Image & Video Tokenization
HYDRA-X, a novel Vision Transformer-based UMM, unifies image and video tokenization, enhancing editing consistency and performance through causal attention and latent-level manipulation.

Images as the New Reasoning Medium
This paper introduces optical reasoning, enabling images to serve as the primary medium for LLM and MLLM reasoning, achieving higher token efficiency and competitive performance.

Gemini's Audio Stack: From Transcription to Music Generation
Google DeepMind's Thor Schaeff explores Gemini's audio stack, from advanced transcription to music generation with Lyria 3.

Google's Gemma 4 12B: AI on Your Laptop
Google's Gemma 4 12B model brings efficient, multimodal AI directly to laptops with a novel unified architecture.

Together AI Masters MiniMax M3 Inference
Together AI details engineering feats enabling efficient MiniMax M3 inference, unlocking 1M-token context and multimodality.

Symbolic Meta-Verification Boosts Multimodal AI
New research on multimodal meta-verification shows symbolic rationales and decoupled RL significantly enhance AI verifier performance and enable agentic self-correction.

Omar Sanseviero on Google's AI Strategy
Omar Sanseviero from Google DeepMind discusses Google's AI strategy, focusing on efficient models, multimodality, and open innovation in AI.

Violin: AI Translates Video Content
Together AI launches Violin, an open-source AI tool for video translation and interactive content analysis.

Beyond RGB: Grounding Vision-Language on Raw Sensor Data
PRISM-VL advances vision-language models by grounding them in raw camera measurements, not just RGB, significantly improving performance on challenging visual tasks.

AlphaGRPO: Reasoning-Enhanced Multimodal Generation
AlphaGRPO framework enhances multimodal generation via GRPO and DVReward, enabling reasoning and self-correction without cold-start, validated across benchmarks.

AI's Next Leap: Interaction Models
Thinking Machines Lab introduces 'interaction models' for AI, enabling real-time, multimodal collaboration that mirrors human conversation.

Architectural Interactivity, Linguistic Interpretability, and Molecular Synthesis: The Frontier of Native AI
Three organisations now define the frontier of native AI: Thinking Machines is rebuilding human-AI collaboration as a low-latency interaction model, the Effable movement wants interpretable safety frameworks like SafetyAnalyst, and Isomorphic Labs is converting AlphaFold into an end-to-end drug design engine. The common thread is moving from AI as a layer of abstraction toward AI as a fundamental component of human and biological systems.
Thinking Machines Lab Wants to Replace OpenAI Realtime With a Model That Listens While It Speaks
Mira Murati's lab published its first technical paper, arguing that real-time interactivity should be a native model capability rather than scaffolding bolted around turn-based language models, and it ships benchmarks where GPT Realtime-2 scores near zero.

AI Archives: Water Data Gets Searchable
Databricks uses multimodal AI to turn Sudan's scanned water archives into a searchable database for critical groundwater discovery.

Together AI Adds NVIDIA Nemotron 3
Together AI launches NVIDIA's Nemotron 3 Nano Omni, a unified multimodal AI model, to developers, simplifying agentic application creation.

Verifiable Reasoning in MLLMs
The V-tableR1 framework enables verifiable, multi-step reasoning in MLLMs by grounding logic in visual data, achieving SOTA on tabular benchmarks.

Google DeepMind's Gemma 4 Models Shine at AI Engineer Europe
Google DeepMind's Omar Sanseviero shared insights into the Gemma 4 family of open AI models at AI Engineer Europe, highlighting their performance, on-device capabilities, and community adoption.

Beyond Black-Box: Structuring Humor AI Reasoning
New IRS framework moves beyond black-box AI, structuring humor understanding via explicit incongruity-resolution reasoning for expert-level performance.

Anthropic's Claude Opus 4.7 Arrives, Sharper Than Ever
Anthropic unveils Claude Opus 4.7, boosting AI's coding prowess, multimodal input, and safety features for enterprise use.

Rubric-Driven DPO for Visual Tasks
A new rDPO framework uses instance-specific rubrics to create high-quality preference data, dramatically improving multimodal AI evaluation and performance.

Bridging Vision Tools and LLMs with P2
Perception Programs (P2) transforms raw vision tool outputs into structured summaries, dramatically enhancing MLLM reasoning without retraining.

Agentic Models Bypass Tool Reliance
HDPO framework enables agentic multimodal models to drastically reduce tool use by decoupling accuracy and efficiency optimization, fostering self-reliance without performance loss.
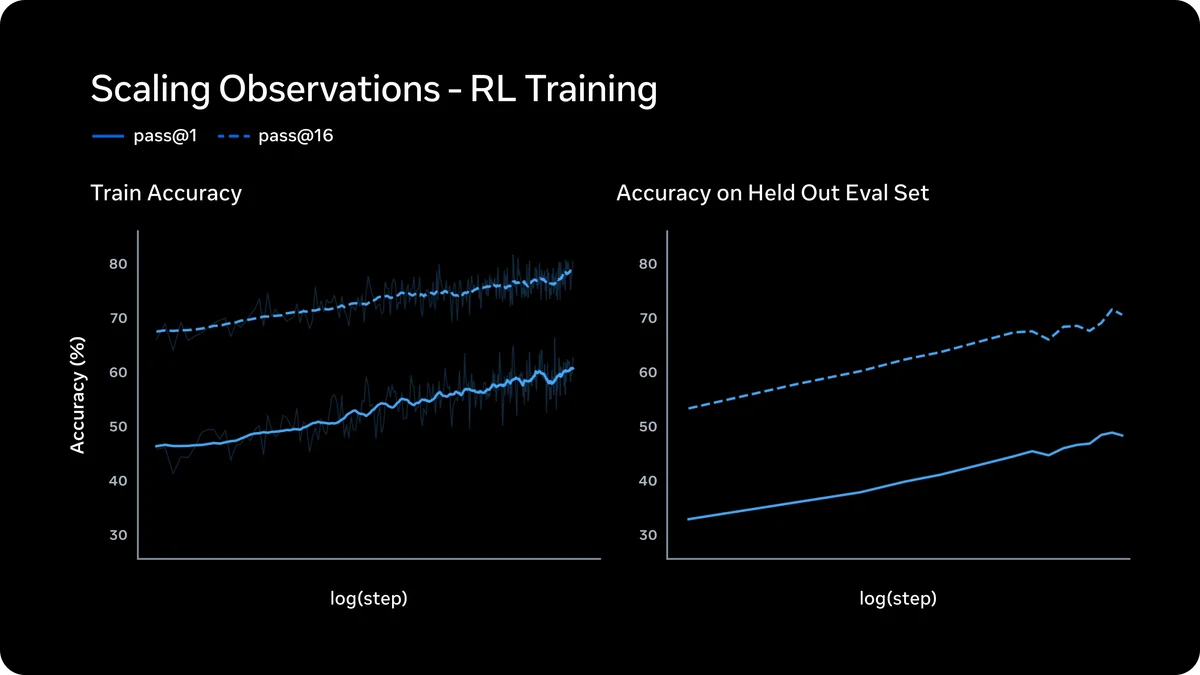
Meta's Muse Spark: AI's Next Act?
Meta unveils Muse Spark, a new multimodal AI model targeting 'personal superintelligence' with advanced reasoning and agent capabilities.

IBM Master Inventor Explains Multimodal AI
IBM Master Inventor Martin Keen explains the evolution of multimodal AI, contrasting feature-level fusion with native multimodality and the importance of temporal reasoning for video.

Mistral AI's Vox-Trainer and Fine-Tuning
Mistral AI announces Vox-Trainer, a new multimodal AI model for voice cloning and speech generation, alongside new benchmarks for speech understanding.

PRIMO R1: Active Critics for Robotic Manipulation
PRIMO R1 transforms video MLLMs into active critics for robotic manipulation via outcome-based RL, achieving SOTA on RoboFail and outperforming larger models.

Mistral Small 4 Unifies AI Capabilities
Mistral AI unveils Mistral Small 4, a unified model combining text, image, reasoning, and coding capabilities under an open-source license.

Code-Driven Reasoning for Precise Image Generation
CoCo (Code-as-CoT) introduces executable code as a reasoning framework for text-to-image generation, achieving superior precision and control.

AI Learns Beyond Text
AI is moving beyond text, with multimodal pretraining enabling models to learn from images, audio, and video for richer comprehension.

Crab+ Unifies AV-LLMs, Reverses Negative Transfer
Crab+ introduces a novel approach to Audio-Visual Large Language Models, overcoming negative transfer via explicit cooperation in data and model design.
Microsoft's Phi-4-reasoning-vision-15B compact AI model
Microsoft Research's Phi-4-reasoning-vision-15B offers efficient multimodal AI, excelling in reasoning and vision tasks with less data and compute.
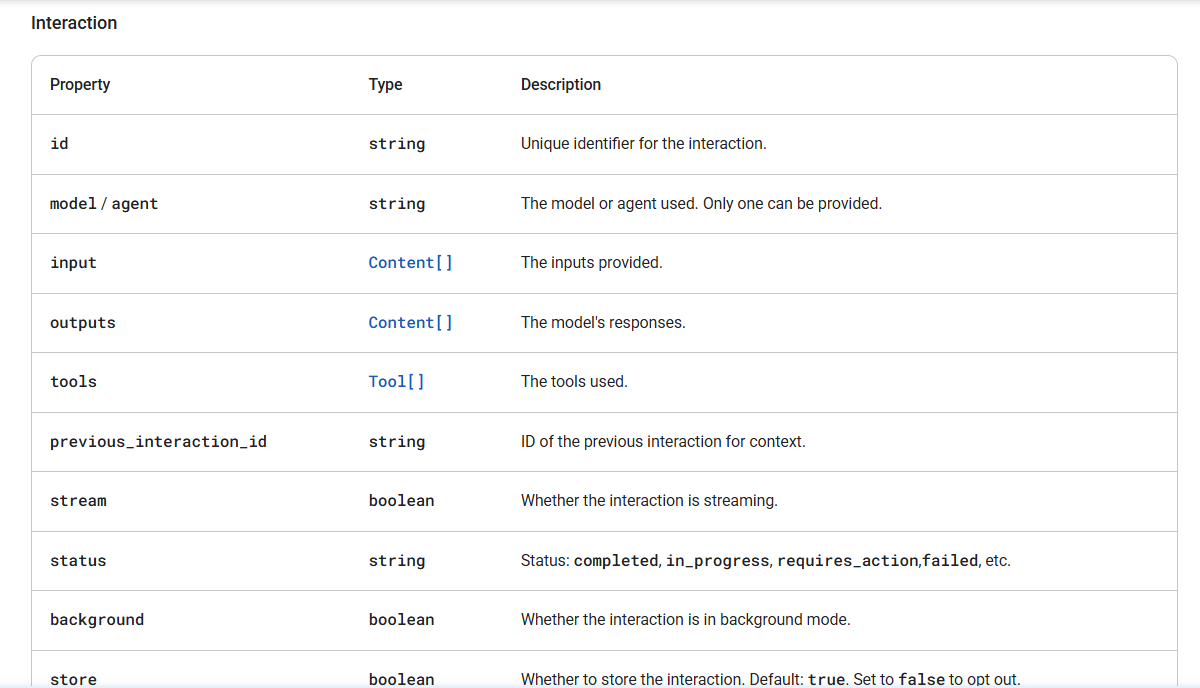
Google's Interactions API Evolves Gemini
Google's new Interactions API for Gemini models offers a unified interface for complex AI tasks, supporting multimodal inputs, agents, and tool integration.
Multimodal LLMs: What's Lost in Translation?
New research reveals multimodal LLMs struggle to utilize non-textual data due to a 'mismatched decoder problem,' impacting their true understanding.
Less Data, More Alignment: SOTAlign
Researchers introduce SOTAlign, a framework that achieves robust cross-modal alignment using significantly less paired data by leveraging unpaired samples.

Agentic Vision Gemini 3 Flash: Code Execution Solves Visual Hallucination
Agentic Vision Gemini 3 Flash shifts multimodal AI from static image processing to an active, code-driven investigation, dramatically improving accuracy and verifiability.

Sparkli AI raises $5M to kill the EdTech chatbot for kids
Sparkli AI, founded by Google alums, raised a $5 million pre-seed round to develop a multimodal, simulation-based learning engine for children aged 5 to 12.
Argos Framework Delivers Grounded AI Reasoning
Argos is an agentic verification framework that fundamentally changes reinforcement learning by rewarding models only for Grounded AI reasoning based on verifiable evidence.

Gemini API Data Ingestion Gets Production Ready
Google has upgraded Gemini API data ingestion to support persistent storage via GCS registration and external signed URLs, boosting the inline limit to 100MB.

The AI Pet Startup That Claims to Translate Your Dog's Thoughts
Google Gemini 3 Redefines AI Reasoning and Efficiency

Google AI Tips: A Year of Ubiquitous Intelligence

T5Gemma 2 Multimodal Ushers In Efficient AI Future

Tinker launches OpenAI API compatibility, challenging vendor lock-in.
Gemini Google Translate Elevates Nuance

Gemma 3n Powers Real-World Impact at the Edge
FACTS Benchmark Suite Elevates LLM Factuality Scrutiny

AI Precision Oncology Gets Scalable Boost from Microsoft AI

Google's Gemini 3 Ushers In The Latest AI Era
