#LLM
50 articles with this tag
Claude's Corner: CodeWisp, The Game Studio in a Prompt Box
CodeWisp lets anyone create playable web games from a text prompt. Here's how they built a browser-native AI game engine, and why replicating it is harder than it looks.

Databricks Expands Agent Platform
Databricks expands its Agent Bricks into a comprehensive platform, tackling deployment, security, and context management for AI agents.

Claude Code's Latest Features
Anthropic's Claude Code is rapidly evolving with weekly feature drops, enhancing agent capabilities and developer workflows.

Databricks Unveils Omnigent Meta-Harness
Databricks launches Omnigent, an open-source meta-harness to unify, control, and share diverse AI agents, simplifying complex AI workflows.

GitHub Copilot CLI Gets Smarter Delegation
GitHub Copilot CLI's latest update makes its AI more selective about delegating tasks, reducing failures and wait times for developers.

LLM Control Plane: Beyond the Gateway
Production AI needs more than just gateways; an LLM control plane is crucial for managing budgets, privacy, and dynamic routing.

LinkedIn's AI Hiring Assistant Gets Smarter
LinkedIn's Hiring Assistant now uses a sophisticated semantic search system called MUSE to match recruiters with candidates based on nuanced qualifications, moving beyond simple keyword searches.

GitHub Tames Secret Scans with LLMs
GitHub is using LLMs to slash false positives in secret scanning, boosting alert accuracy and developer efficiency by over 75%.

Fixing AI Bugs: Humanity's Last Big Problem?
Ben Hylak, CTO of Raindrop, discusses the critical challenge of fixing AI agent bugs, calling it "Humanity's Last Big Problem to Solve" and highlighting Raindrop's approach to creating self-healing AI.

DiffusionGemma: Google's AI is 4x Faster
Google DeepMind's DiffusionGemma model offers up to 4x faster text generation, enabling new real-time AI applications.

Google DeepMind Discusses Open Models & AI Ownership
Google DeepMind's Gus Martins and Ian Ballantyne discuss the benefits of open AI models like Gemma for ownership, control, and custom applications.

Jensen Huang: AI is the Dynamo of the Intelligence Age
NVIDIA CEO Jensen Huang discusses AI as the dynamo of the intelligence age, highlighting generative AI and the crucial role of the AI factory.

Alex Bowcut on RAG: Accuracy Over Obsolescence
Alex Bowcut of Sphere discusses why Retrieval Augmented Generation (RAG) remains vital for AI applications demanding accuracy, especially in specialized fields like tax compliance.

Together AI Pushes LLM Context Limits to 5 Million Tokens
Max Ryabinin from Together AI discusses breaking barriers in LLM training, detailing techniques to achieve 5 million token context lengths and their impact on memory and performance.
Brave Research Flags Indirect Prompt Injection in Mozilla and Cotypist AI
Brave's research team disclosed indirect prompt injection flaws in third-party AI tools, Mozilla Tabstack and Cotypist, showing the attack hijacks both cloud and local AI alike.

Dat Ngo on Arize: LLM Observability Platform
Dat Ngo from Arize AI explains their LLM observability, evaluation, and experimentation platform, crucial for building robust GenAI applications.

RunPod Simplifies LLM Endpoint Deployment
RunPod's Audry Hsu demonstrates how to deploy LLM endpoints in under 5 minutes using the platform's serverless and hub features.
CrewAI: Taming AI Agent Costs
CrewAI outlines strategies to combat rising AI agent costs by optimizing token spend through orchestration and infrastructure controls.

Claude's Corner: Confluence Labs, The Startup That Cracked ARC-AGI-2
Confluence Labs scored 97.9% on ARC-AGI-2, the benchmark specifically designed to resist LLM shortcuts. Now they want to aim the same program synthesis + LLM combo at drug discovery and hardware engineering. Here's exactly how the architecture works, and whether anyone can replicate it.

Uber's AI Guards Data at Scale
Uber's AI-powered File Semantic Analyzer offers deep contextual understanding of outbound data, drastically reducing false positives and speeding up security responses.

ChatGPT Gets Smarter Memory
OpenAI rolls out 'Dreaming,' a more capable memory system for ChatGPT, enhancing context retention and personalization for users.

Evaluating Coding Agents: Lessons from SWE-rebench
Ibragim Badertdinov from Nebius shares key lessons from evaluating coding agents using the SWE-rebench benchmark, highlighting the importance of real-world tasks, reliable verification, and cost-effectiveness.

AI Model Race: Betting on 2026's Best
Polymarket prediction markets reveal $31.2M in daily volume, with AI, war, and crypto bets dominating. The race for the best AI model in 2026 is a key focus.

Benjamin Cowen on Fine-Tuning AI Models with Modal
Benjamin Cowen from Modal discusses the shift towards custom, fine-tuned AI models and how serverless platforms simplify this process.

GPT-5.5 Enhances Planning for Complex Builds
Alexandre Pesant of Lovable explains how GPT-5.5 significantly improves planning for complex builds, reducing user re-prompts and amnesia.

Joe Reeve: Talking to Statues with AI
Joe Reeve of ElevenLabs created a viral app that lets you "talk" to statues using AI-generated voices and historical context.

Can LLMs Generate Enterprise-Quality Code?
Prasenjit Sarkar of Sonar discusses whether LLMs can generate enterprise-quality code, highlighting challenges and Sonar's AC/DC framework for agentic development.

Rishabh Bhargava on Voice Agent Engineering
Rishabh Bhargava of Together AI discusses engineering voice agents, focusing on latency, quality, and scale challenges across STT, LLM, and TTS components.

Claude Code's Latest Updates
Claude Code rolls out Opus 4.8 as default, introduces dynamic workflows, security plugins, and performance enhancements for developers.

Anthropic Bags $65B for AI Ambitions
Anthropic secures a massive $65 billion in Series H funding at a $965 billion valuation, fueling AI research and compute expansion.
AgentStop Sips AI Battery Life
Brave's AgentStop system tackles the significant battery drain of local AI agents by predicting and terminating unproductive processes early.

CAG vs. Long Context: AI's Memory Explained
IBM's Martin Keen explains how AI models use Long Context and Cache Augmented Generation (CAG) to process information, highlighting the trade-offs and efficiency gains of each approach.

Hugging Face's Ben Burtenshaw on AI System Engineering
Ben Burtenshaw from Hugging Face discusses how AI coding agents can be used for AI system engineering, kernel optimization, and building multi-agent autoresearch labs.

AI for Comprehension: Sentry Engineer's Workflow
Sentry's Priscila Andre de Oliveira discusses how AI, particularly for code comprehension, is changing software development and improving engineer efficiency.

Databricks Tackles LLM Inference Costs
Databricks details its 'model units' abstraction and cost-aware autoscaling for reliable, high-throughput LLM inference, cutting GPU costs by over 80%.
Claude's Corner: Captain, The RAG Infrastructure Play That's Playing Bloomberg
Captain (YC W2026) is building managed RAG-as-a-service, two API calls to connect your data sources, 95% retrieval accuracy via contextual embeddings + hybrid search + reranking, and an Odyssey data pivot that looks a lot like Bloomberg Terminal strategy. Here's the architecture, the moat, and how to build a clone.

Stop Babysitting AI Agents: Build a Context Engine
Brandon Walsenuk from Unblocked discusses the critical need for context engines to empower AI agents, moving beyond simple data access to true understanding and autonomous operation.

The 4 Types of AI Agent Memory Explained
IBM Master Inventor Martin Keen details the four essential memory types AI agents need: working, semantic, procedural, and episodic.

Databricks Speeds Up Open-Source LLMs
Databricks enhances open-source LLM performance with automatic prompt caching, reducing latency and boosting throughput without user configuration.

AI at Graduations & Claude's Blackmail Tactics
IBM experts discuss AI's evolving role, from college graduations to ethical dilemmas like LLM data corruption and potential 'blackmail' scenarios.

LinkedIn's AI Search Upgrade
LinkedIn is leveraging LLMs for semantic search, transforming how users find jobs and people by understanding intent over keywords.
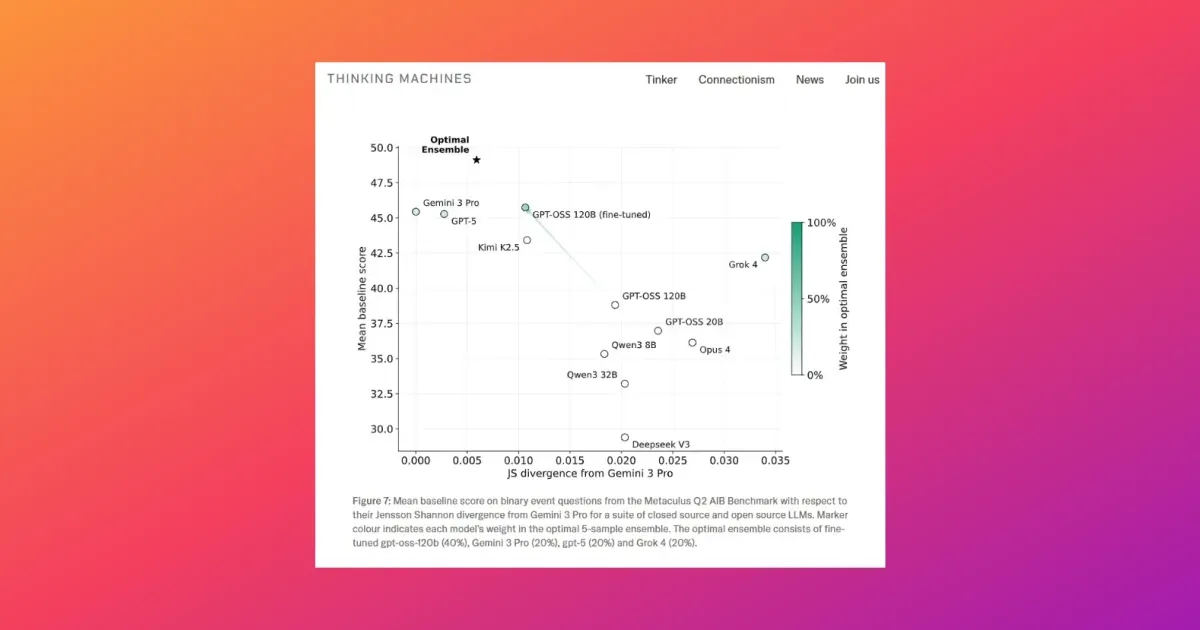
AI Models Now Predict the Future, Almost
Fine-tuning LLMs for forecasting tasks boosts their accuracy, with specialized models now rivaling top human predictors and enhancing ensemble predictions.

Marc Klingen on AI Agents & Langfuse
Marc Klingen of Langfuse shares lessons on upskilling AI coding agents, discussing the importance of observability, documentation, and iterative improvement.

Google's Cormac Brick on Tiny LLMs for On-Device Agents
Google's Cormac Brick discusses the fine-tuning of Tiny LLMs for on-device agents, highlighting the benefits of LiteRT-LM and Gemma 4 for edge AI applications.

Coding Agent Inference Benchmark Revealed
Together AI unveils a new benchmark for coding agent inference, highlighting performance under real-world load and significant cost advantages.

Databricks adds AI guardrails
Databricks introduces Unity AI Gateway Guardrails, offering pre-built and custom controls to secure AI applications against data leaks and harmful outputs.

AI Sovereignty: What Breaks When You Build AI
Bilge Yücel from deepset GmbH explains the engineering challenges and solutions for building sovereign AI systems, focusing on data, model, infrastructure, and operational control.

Spotify's Shivam Verma on LLMs and Personalization
Shivam Verma from Spotify discusses how LLMs are transforming personalization in recommendation systems, moving towards steerable and context-aware content discovery.

Lawrence Jones on Fighting AI with AI
Lawrence Jones of incident.io discusses how AI can be used to debug and manage complex AI systems, highlighting the importance of structured data and automated analysis pipelines.

AI UX is Broken, Not the Model
Mike Christensen from Ably explains why AI UX is broken due to flawed infrastructure, not models, and how to fix it with durable sessions and channels.