#Evaluation
10 articles with this tag

Dat Ngo on Arize: LLM Observability Platform
Dat Ngo from Arize AI explains their LLM observability, evaluation, and experimentation platform, crucial for building robust GenAI applications.

LLM Evaluators: Beyond Naive Judgments
Mahmoud Malaeb of Argenta discusses the limitations of naive LLM judges and introduces GEPA, an optimization framework for building more accurate LLM evaluators using a data flywheel approach.
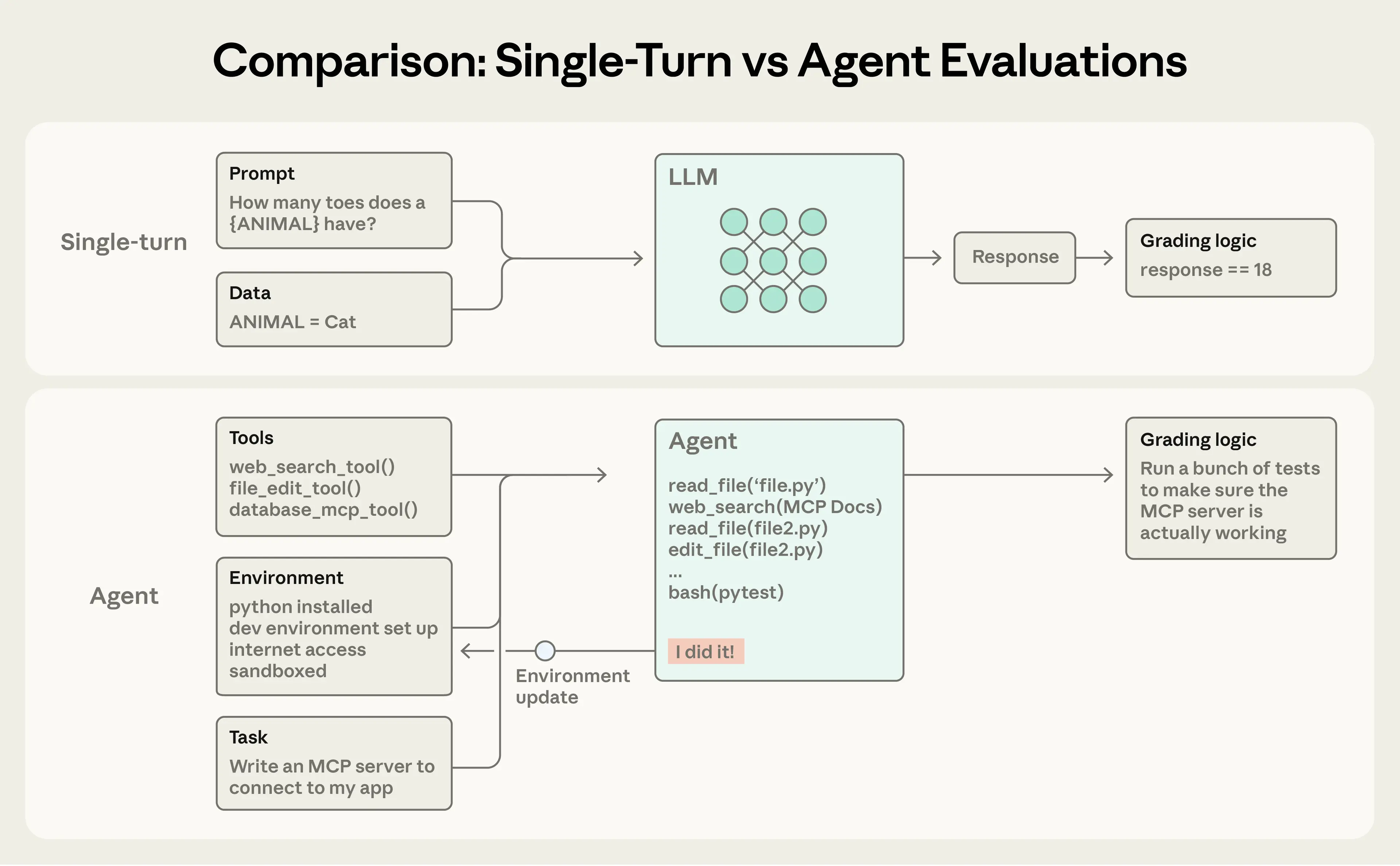
The Hidden Cost of Autonomy: AI Agent Evaluation

OpenAI Says Business AI Evaluation Is the Key to ROI

Evals Reimagined: Braintrust's Engineering Approach to AI Development

Building Reliable AI: The Imperative of Application-Layer Evals

DeepMind Proposes Radical Shift in AI Intelligence Benchmarking
Google DeepMind has unveiled a significant new initiative aimed at fundamentally rethinking how artificial intelligence capabilities are measured. In an announcement on its blog, the leading AI research institution detailed a comprehensive framework designed to...

The Unseen Challenge of Reliable AI

The State of AI Engineering: Insights from Amplify's 2025 Report with Barr Yaron
The State of AI Engineering: Insights from Amplify\'s 2025 Report with Barr Yaron
\"Evaluation/evals\" stands as the single most painful aspect of AI Engineering today, a stark revelation from Amplify Partners\' recent 2025 AI Engineering...