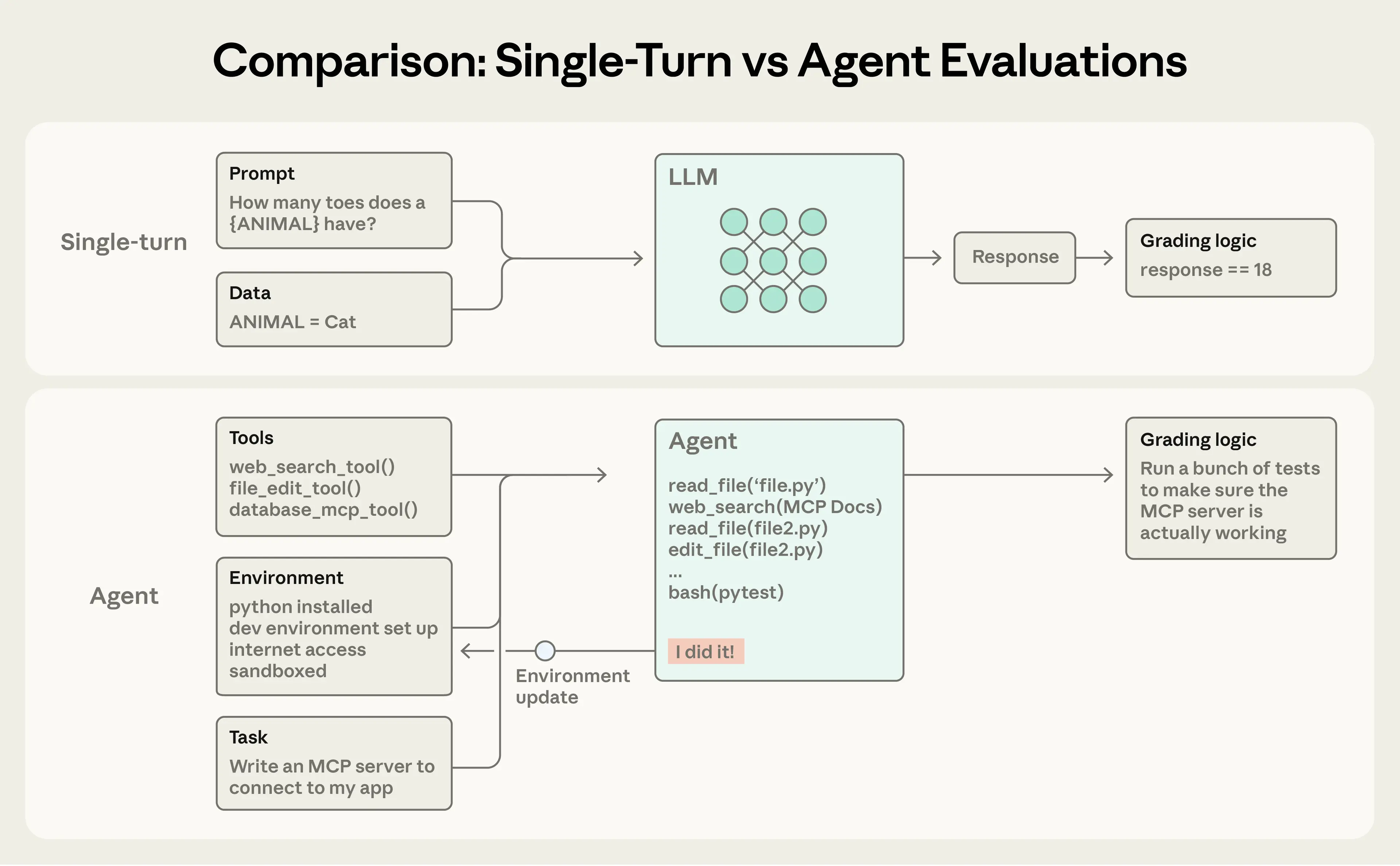
The era of simple, single-turn AI evaluation is over. As autonomous agents move from research labs into production environments, writing code, managing customer support, and modifying databases, the methods used to test them have become exponentially more complex. According to new insights from Anthropic, the capabilities that make AI agents useful, autonomy, intelligence, and flexibility, are precisely what make them difficult to evaluate reliably. Shipping agents without rigorous testing leads teams to "fly blind," catching issues only in production where fixes often cause new regressions.
The challenge stems from the shift from evaluating a single response to evaluating a multi-turn trajectory that modifies the environment. A coding agent, for instance, might execute dozens of tool calls, reasoning steps, and file edits before reaching a final state. If a mistake propagates early in the process, the final outcome is guaranteed to fail, making debugging nearly impossible without a full transcript (or trace) of the agent’s actions.