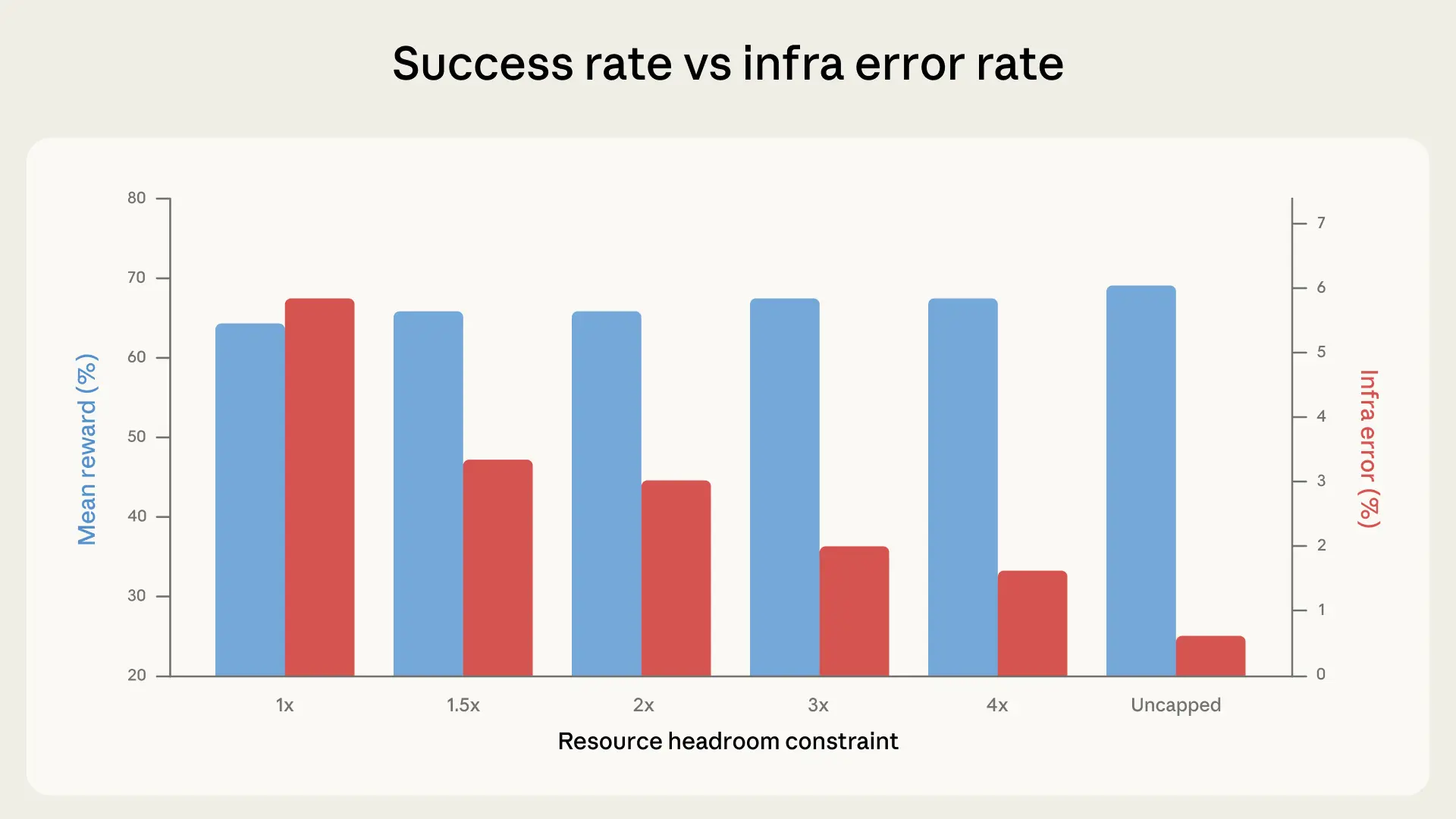
The race to build the smartest AI is getting complicated. Benchmarks designed to measure the coding prowess of cutting-edge models, like agentic coding benchmarks such as SWE-bench and Terminal-Bench, often show top models separated by mere percentage points. These scores are treated as gospel for deciding which AI to deploy, but new research reveals a significant flaw: the underlying infrastructure can distort results more than the models themselves.
Internal experiments found that simply changing the server resources allocated to resource configuration impact, specifically on Terminal-Bench 2.0, created a 6-percentage-point difference in scores. This gap is wider than the margin separating leading AI models.