#Benchmarking
18 articles with this tag

FrontierCode: AI Coding Benchmark Goes Beyond Correctness
Cognition's FrontierCode benchmark redefines AI code evaluation, measuring real-world 'mergeability' and finding current models fall short of production standards.

Claude Code Benchmarking: Semantic Search vs. Grep
Turbopuffer's Kuba Rogut benchmarks semantic code retrieval on Claude Code, revealing how semantic search enhances AI agent precision and efficiency compared to grep.
Bertrand Charpentier on AI Benchmarking Challenges
Bertrand Charpentier of Pruna AI discusses the challenges in AI benchmarking, the limitations of public leaderboards, and the importance of considering both quality and efficiency.

Coding Agent Inference Benchmark Revealed
Together AI unveils a new benchmark for coding agent inference, highlighting performance under real-world load and significant cost advantages.

Agentic RLHF Needs New Benchmarks
New benchmark Plan-RewardBench reveals current RMs struggle with agentic tool use and long-horizon tasks, highlighting the need for specialized trajectory-level reward modeling.

ClawBench: Testing Real-World AI Agents
ClawBench, a new evaluation framework, tests AI agents on real-world online tasks across live platforms, revealing significant performance gaps in current frontier models.

Medical VLMs Fail Critical Input Sanity Checks
Medical VLMs fail critical input validation tests, as revealed by the new MedObvious benchmark, highlighting a significant safety risk.

Supermemory CEO on AI Memory: "We need to get this right"
Supermemory CEO Dhravya Shah discusses the evolution of AI memory, the company's innovative approach to personalizing AI experiences, and the critical importance of getting memory systems right for the future of AI.

Standardizing Survival HTE Evaluation
Introducing SurvHTE-Bench, the first comprehensive benchmark for evaluating heterogeneous treatment effects in survival data, promoting reproducible and rigorous research.
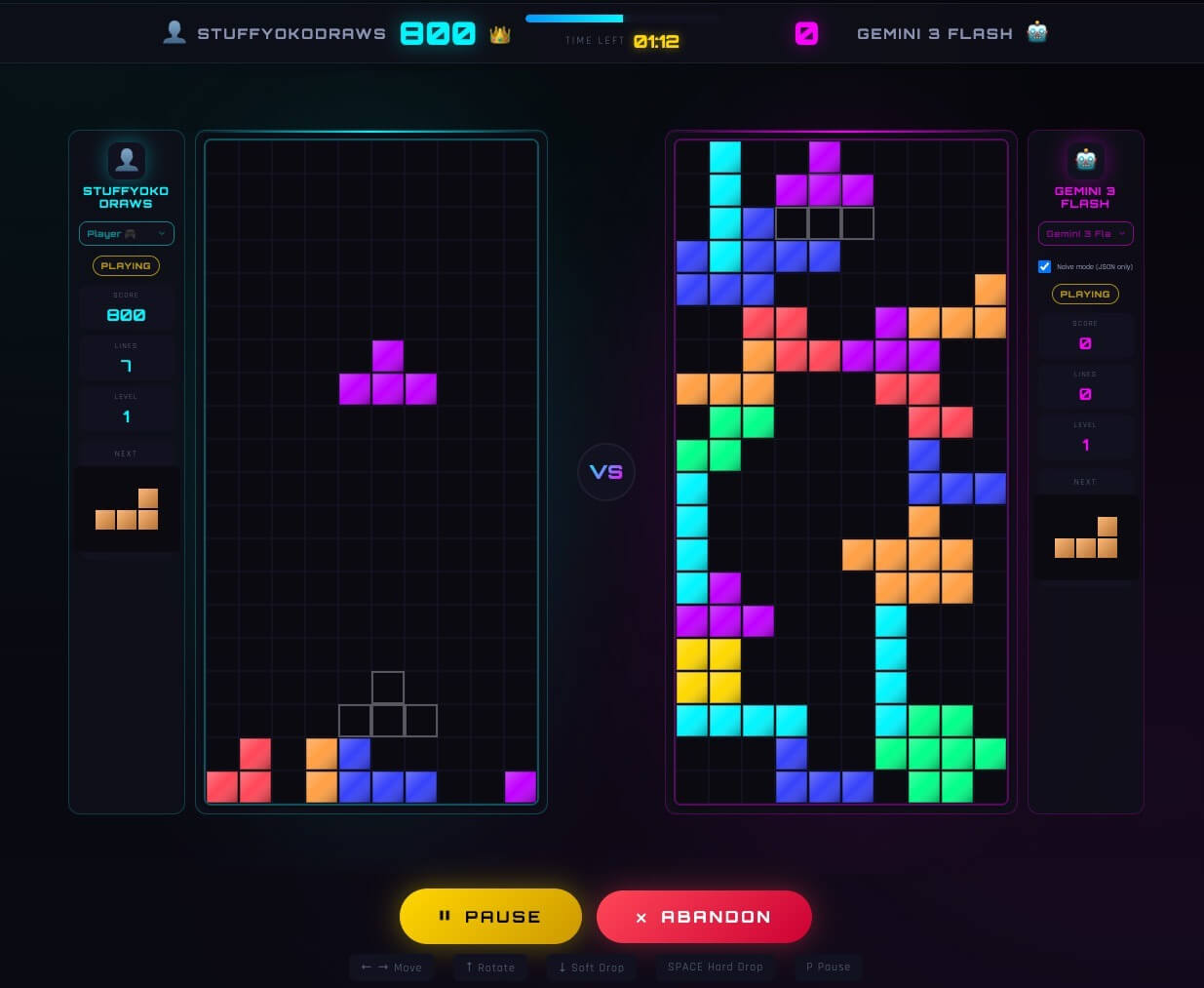
TetrisBench: LLMs Conquer Tetris, Differently
Yoko Li's TetrisBench project reveals how LLMs, initially struggling with direct play, develop surprising, distinct strategies when tasked with generating game logic, outperforming most humans but faltering against top players' adaptive chaos.
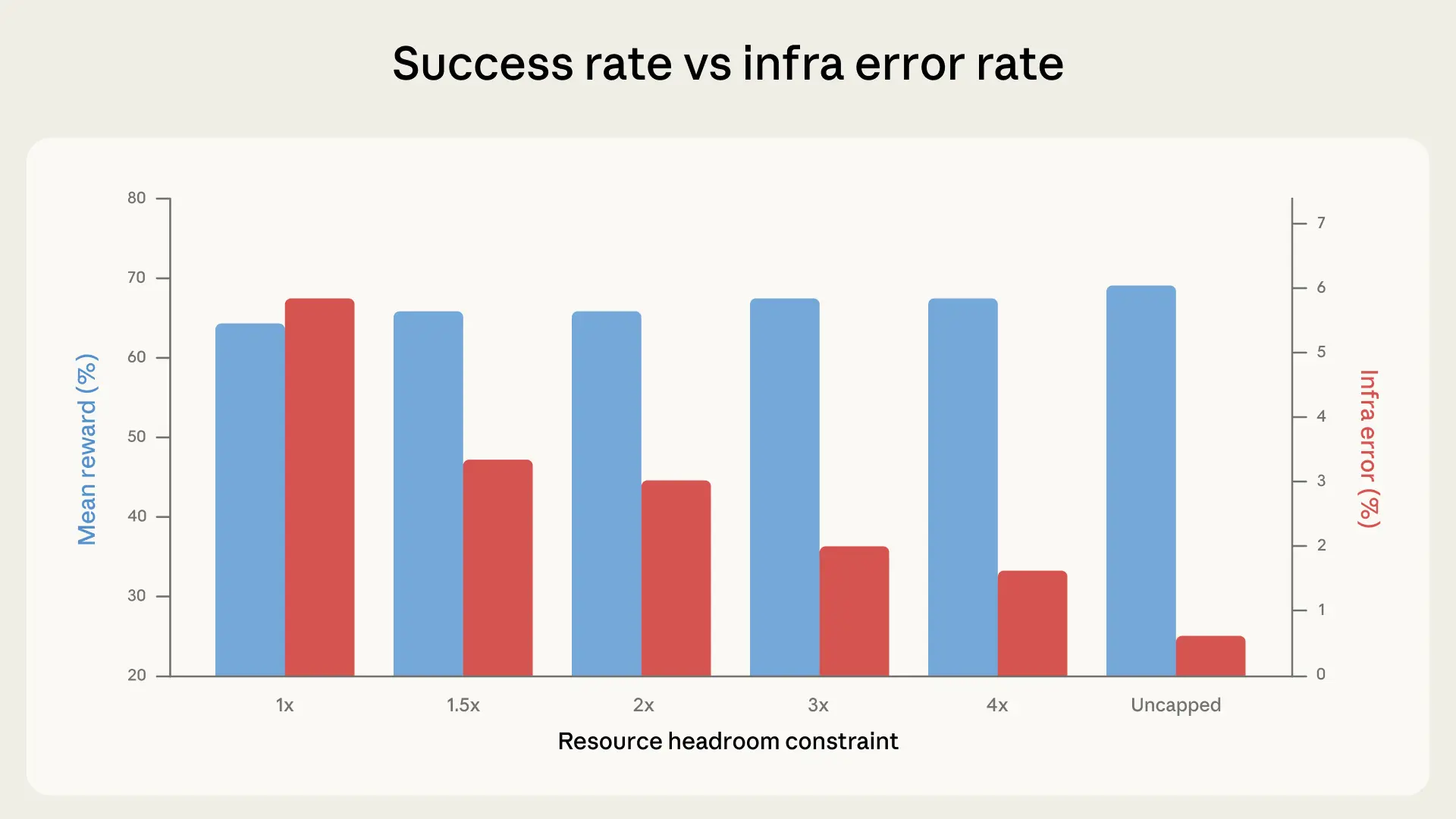
AI Coding Tests Flawed by Infrastructure Noise
The infrastructure powering AI coding tests can significantly inflate or deflate model scores, potentially masking true capabilities and misleading deployment decisions.
FACTS Benchmark Suite Elevates LLM Factuality Scrutiny

AI hits a wall on FrontierMath performance
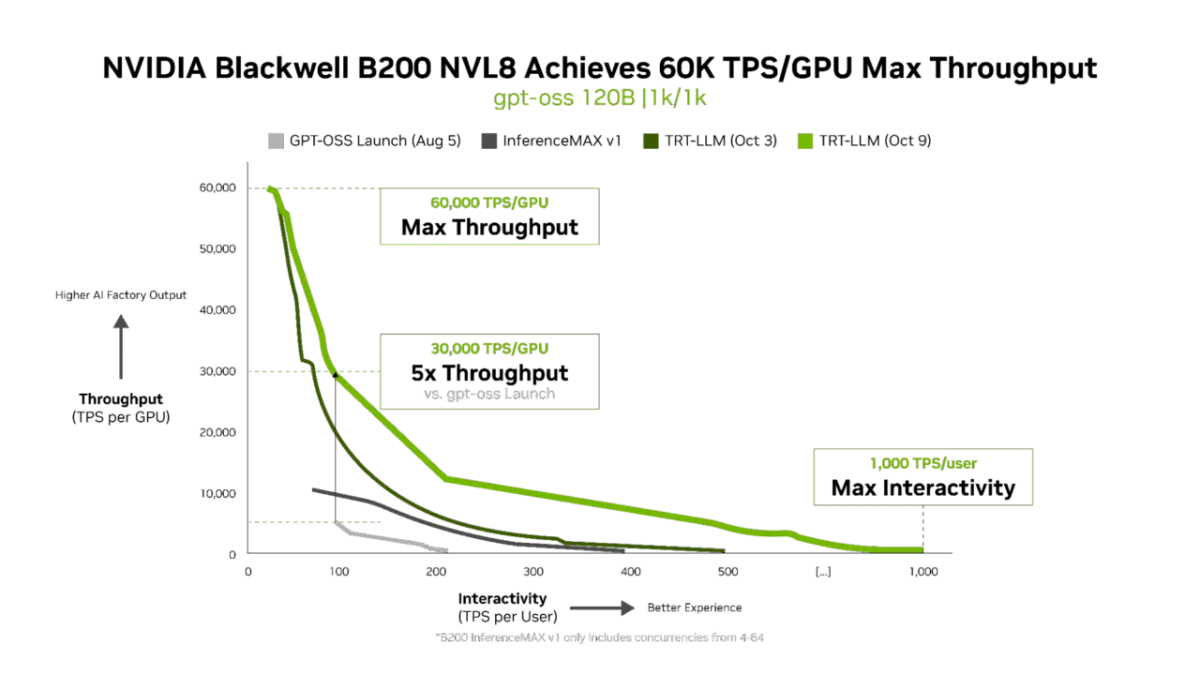
NVIDIA Blackwell benchmarks show staggering AI economics

Salesforce AI, Berkeley Unveil BFCL Audio Benchmark for Voice AI Precision
Salesforce AI Research and UC Berkeley have unveiled BFCL Audio, a new benchmark designed to rigorously evaluate the precision of AI models in handling audio-native function calls. In an announcement on its blog, the collaboration...
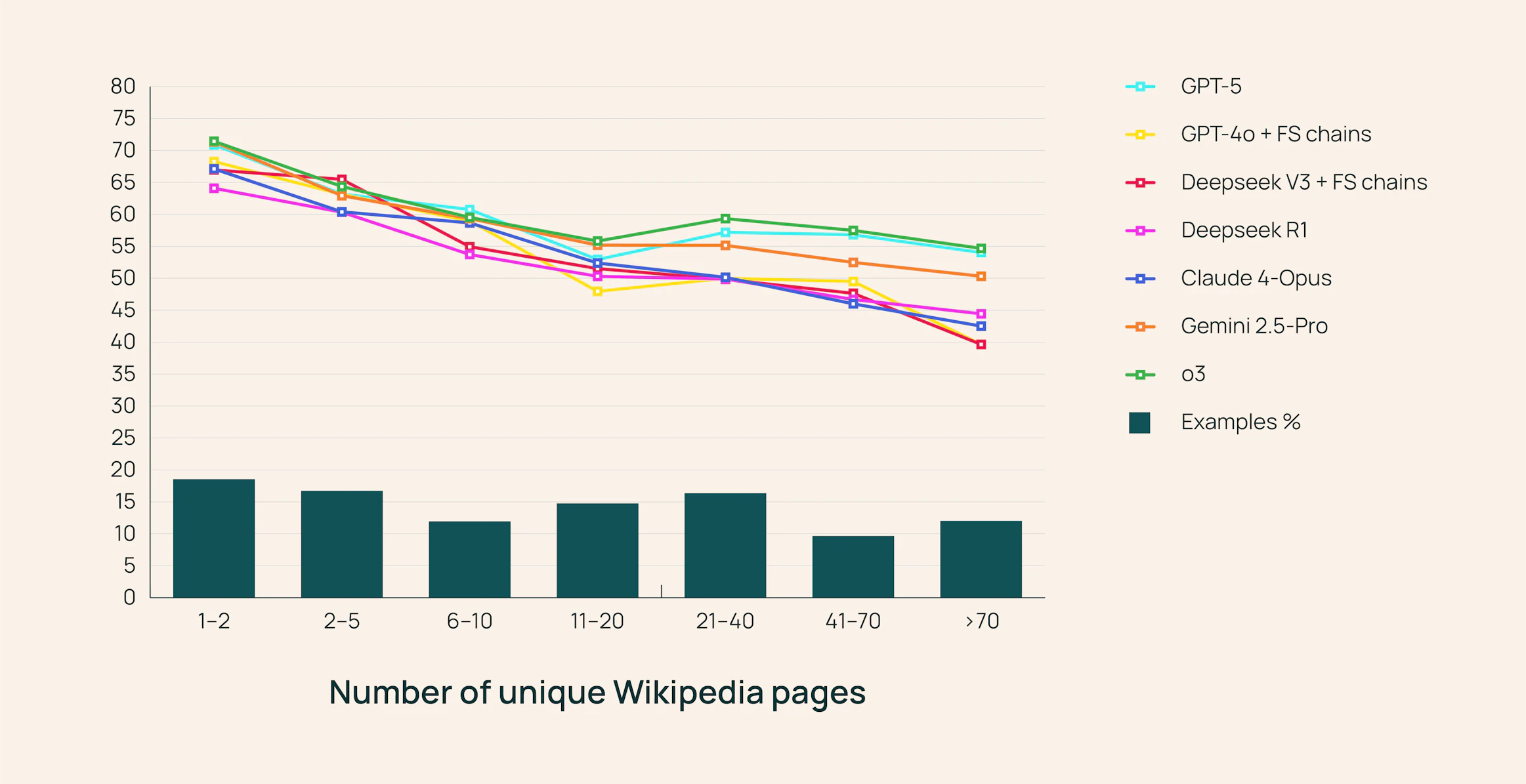
MoNaCo Benchmark: A New Standard for Complex Question Answering
The benchmark exposed weaknesses in today’s most advanced models. Researchers tested 15 frontier LLMs, including GPT-5, Anthropic Claude Opus 4, Google Gemini 25 Pro, and OpenAI’s reasoning-focused o3.
