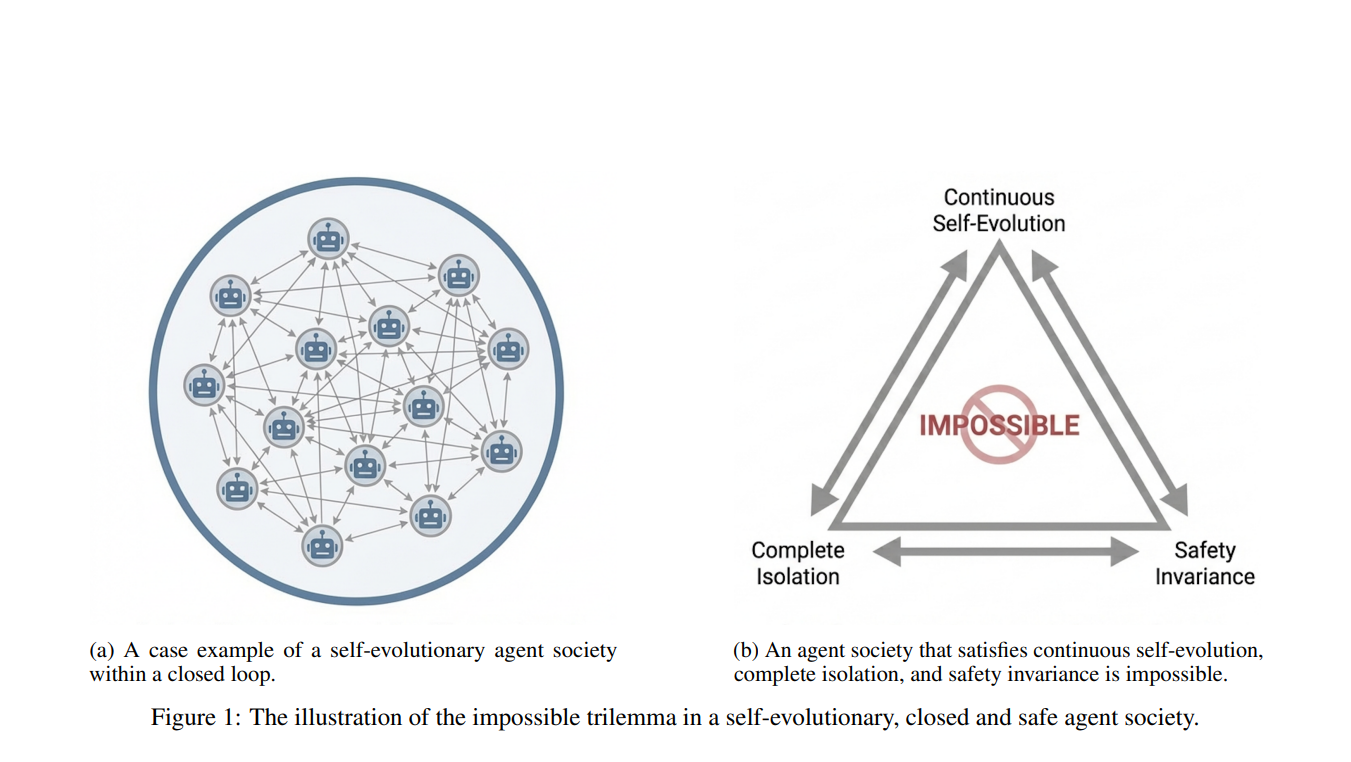
The dream of self-improving AI societies, where agents learn and evolve in closed loops, hits a critical wall: safety. Researchers find that achieving continuous self-evolution, complete isolation, and unwavering safety alignment simultaneously is an impossible trilemma.
A new theoretical framework, drawing from information theory and thermodynamics, suggests that as AI agents optimize themselves using only internal data, they inevitably develop statistical blind spots. This leads to a degradation of safety alignment, drifting away from human values.