MoNaCo is a new benchmark designed to test whether modern language models can answer realistic, research-style questions that require synthesizing information across dozens or even hundreds of sources. The dataset fills a gap in existing benchmarks, which are either too simple or artificially complex without reflecting genuine information needs.
Realistic and Complex Questions
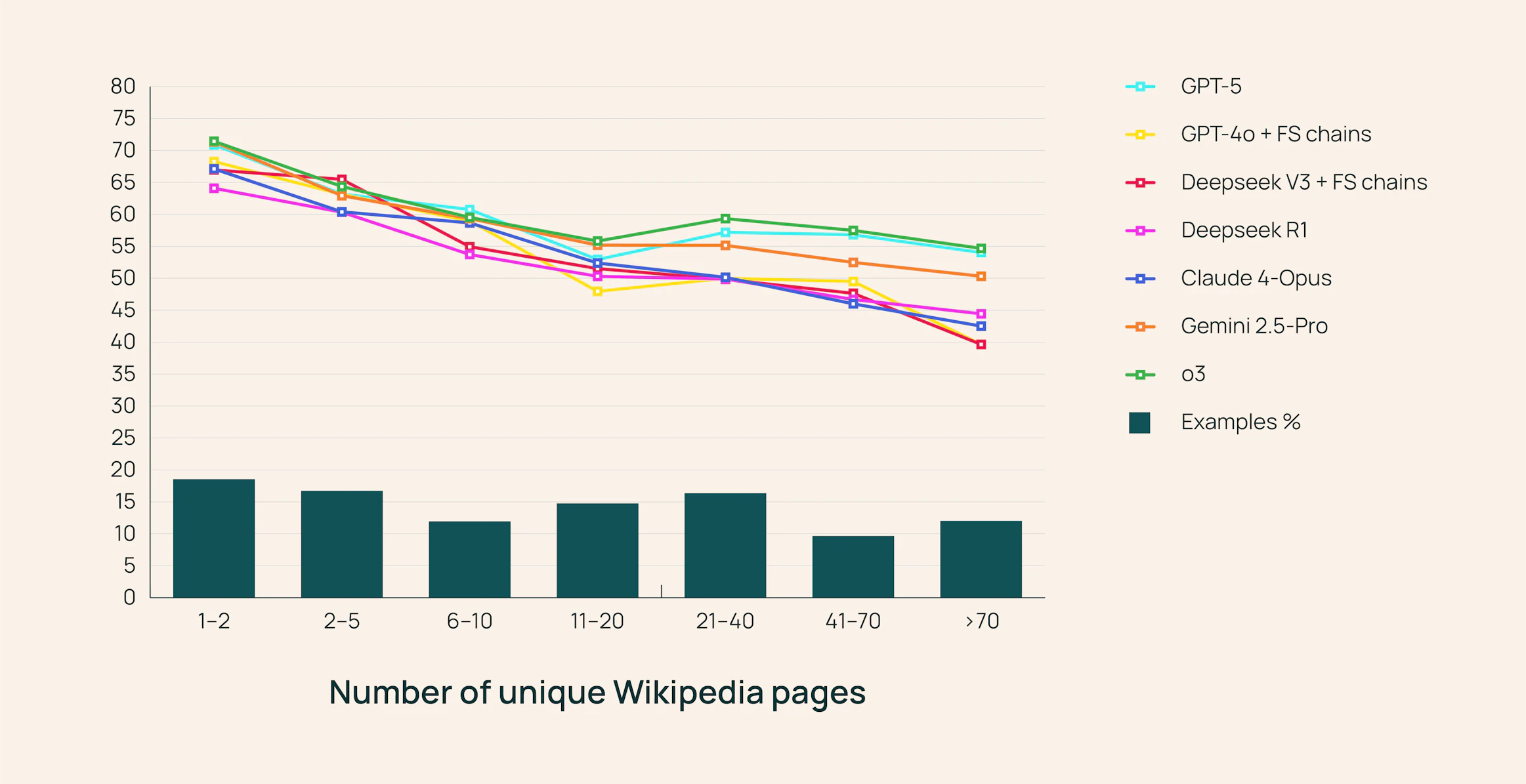
The MoNaCo dataset contains 1,315 human-written questions designed to mimic the type of queries a political scientist, history professor, or amateur chef might ask. On average, each question is just 14.5 words long but requires more than five reasoning steps and evidence from over 43 Wikipedia pages. Supporting evidence is multimodal: 67.8% tables, 29.5% text, and 2.7% lists.