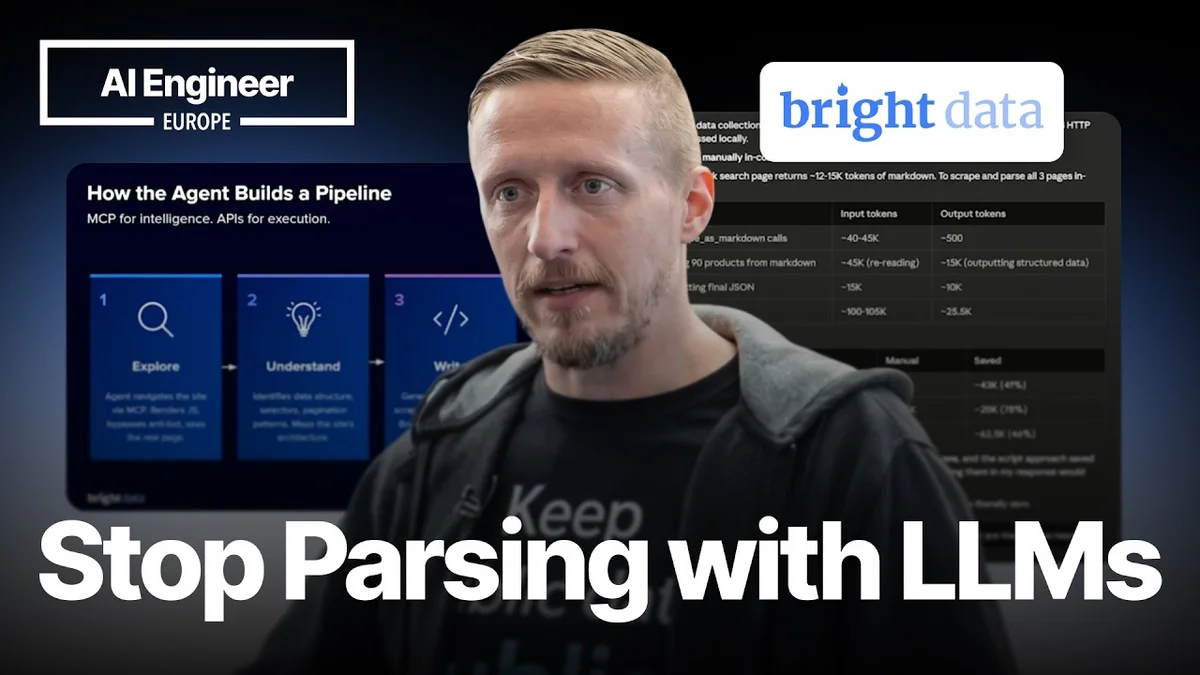
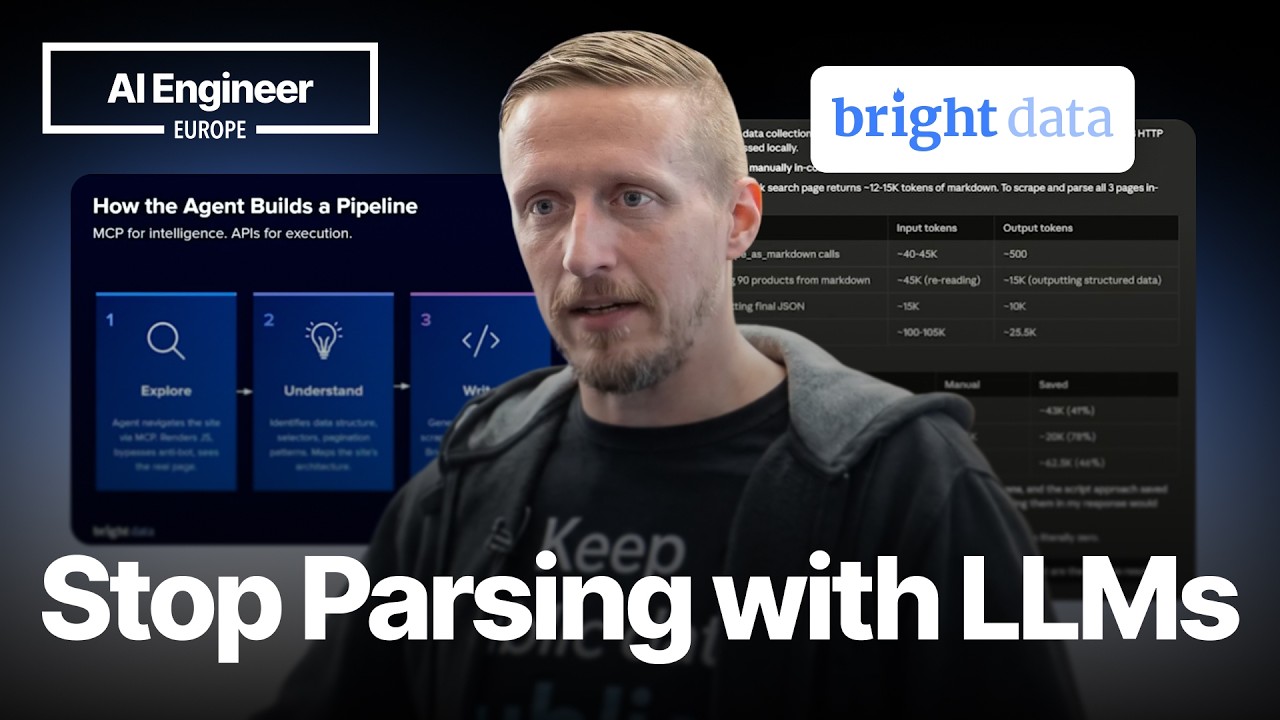
Rafael Levi from Bright Data presented a compelling session on leveraging AI agents to construct self-healing data pipelines. The core of the presentation focused on how AI agents can autonomously navigate, understand, and extract data from websites, ultimately building production-grade web scrapers without human scripting.
The Power of AI Agents in Data Pipelines
Levi explained that traditional web scraping often involves significant manual effort, from writing the initial scraper to ongoing maintenance as websites change. He highlighted the concept of the 'scraper tax,' which encompasses the time spent on site redesign inspection, selector handling, pagination, and debugging. This manual process is prone to errors and time-consuming, especially when dealing with dynamic or frequently updated websites.