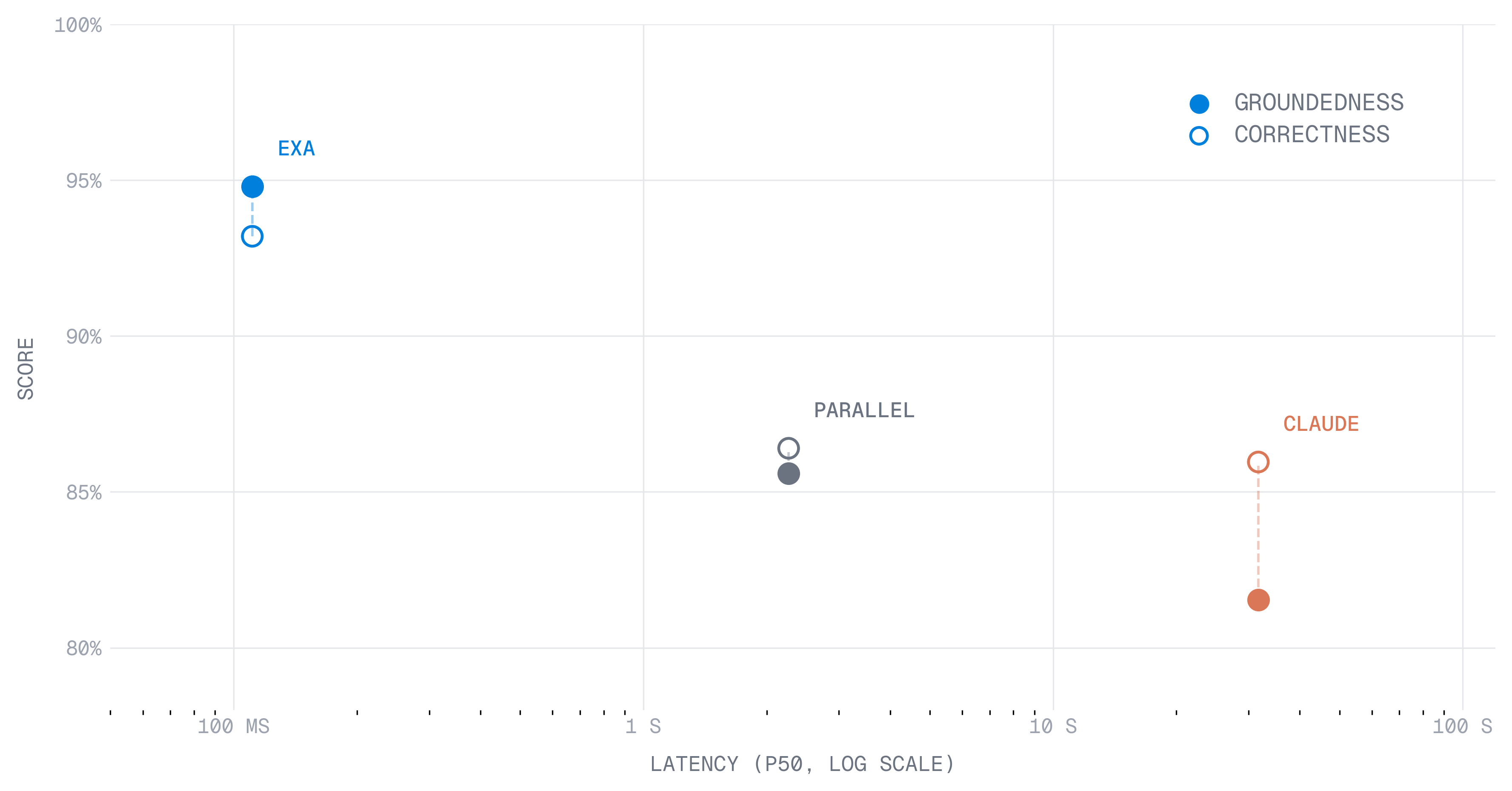
Exa.ai, the AI-powered search engine, is tackling a critical gap in evaluating search capabilities for coding agents. Today, the company is open-sourcing 'WebCode,' a suite of benchmarks designed to rigorously assess how well web search functions serve AI developers. This move comes as Exa observes a significant surge in code search queries over the past year, particularly a sharp increase at the end of 2025. Precision in these results is paramount, as coding agents rely on retrieved context for multi-step reasoning, where stale or noisy data can derail complex processes. Exa has developed a dedicated pipeline to ensure fresh, clean results, prioritizing substantive content over full-page scraping.
The need for robust evaluation methods is underscored by the shortcomings of current public benchmarks. As detailed on exa.ai, these existing tools often fall prey to data contamination and saturation. Models may learn to answer benchmark questions through memorization rather than genuine reasoning, a problem highlighted by OpenAI's recent deprecation of its own SWE-bench Verified benchmark. This issue is particularly relevant for search, where agents must navigate new, niche, or rapidly updating information, such as changelogs and SDK documentation.