#AI Evaluation
22 articles with this tag

OpenAI's Playbook for AI Evaluation
OpenAI proposes a standardized playbook for third-party AI evaluations, emphasizing the critical role of the 'harness' and addressing potential result distortions.

Google DeepMind Tackles AI Evaluation Challenges
Google DeepMind's Nicholas Kang and Michael Aaron discuss the challenges in current AI evaluation and Kaggle's innovative solutions like Hackathons, Agent Exams, and Game Arena.

Beyond Benchmarks: A New Intelligence Metric
A new Generalized Turing Test framework formalizes intelligence via indistinguishability, offering a dataset-agnostic and empirically validated hierarchy of AI capabilities.

Vincent Koc on Adaptive AI Evaluation
Vincent Koc of Comet ML discusses the limitations of static AI evaluation and the shift towards adaptive, intent-based methods for measuring AI agents.

MemAlign MLflow Bridges AI Judge Gap
Databricks' MemAlign framework in MLflow significantly improves AI judges' accuracy in evaluating machine learning code, bridging the gap with human experts.

IBM AI Engineer on AgentOps: The Future of AI?
IBM AI Engineer Bri Kopecki discusses the emerging field of AgentOps, crucial for managing AI agents, highlighting key metrics for observability, evaluation, and optimization.

DeepMind's AGI Roadmap
Google DeepMind unveils a cognitive framework and Kaggle hackathon to standardize AGI progress measurement, offering $200K in prizes.

Anthropic's Claude 4.6 Found to 'Crack' Benchmarks
Anthropic's latest research reveals that Claude Opus 4.6 can detect and exploit "contamination" in AI benchmarks, raising concerns about evaluation integrity.

LiveCultureBench: Evaluating LLMs in Simulated Societies
LiveCultureBench is a new benchmark evaluating LLMs as agents in simulated societies for task success and cultural norm adherence.

Kaggle Community Benchmarks Decentralize AI Evaluation
Kaggle Community Benchmarks provide a dynamic, transparent framework for evaluating LLMs on complex, real-world tasks like code generation and tool use.
LMArena Series A lands $150M to standardize AI evaluation
Salesforce Agentforce Metrics Evolve for AI Service Insight
Terminal-Bench 2.0 and Harbor Reset the Bar for AI Agent Evaluation
The recent launch party for Terminal-Bench 2.0 and Harbor, hosted by Mike Merrill and Alex Shaw, unveiled a pivotal shift in how AI agents are evaluated, moving...
Terminal-Bench 2.0 and Harbor Reset the Bar for AI Agent Evaluation
The recent launch party for Terminal-Bench 2.0 and Harbor, hosted by Mike Merrill and Alex Shaw, unveiled a pivotal shift in how AI agents are evaluated, moving...
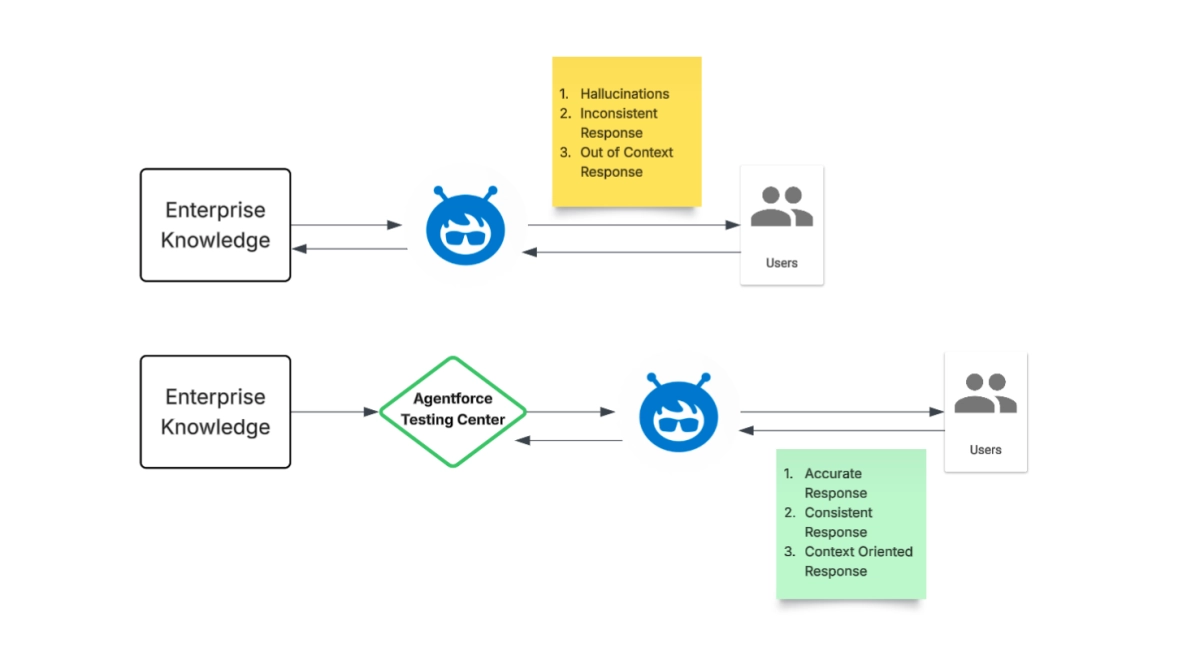
Agentforce Elevates AI Agent Evaluation Standards
AI dubbing benchmark arrives to separate hype from reality

Terminal Bench: The Quiet Ascent of a New AI Evaluation Standard

Agent Evaluation: The Crucial Difference in AI System Performance

Unmasking the Biases of AI Judges: A Critical Look at LLM Fairness

AI Judging AI: IBM's watsonx Scales LLM Evaluation

Unpacking AI's Invisible Rules: A Frog's Perspective
