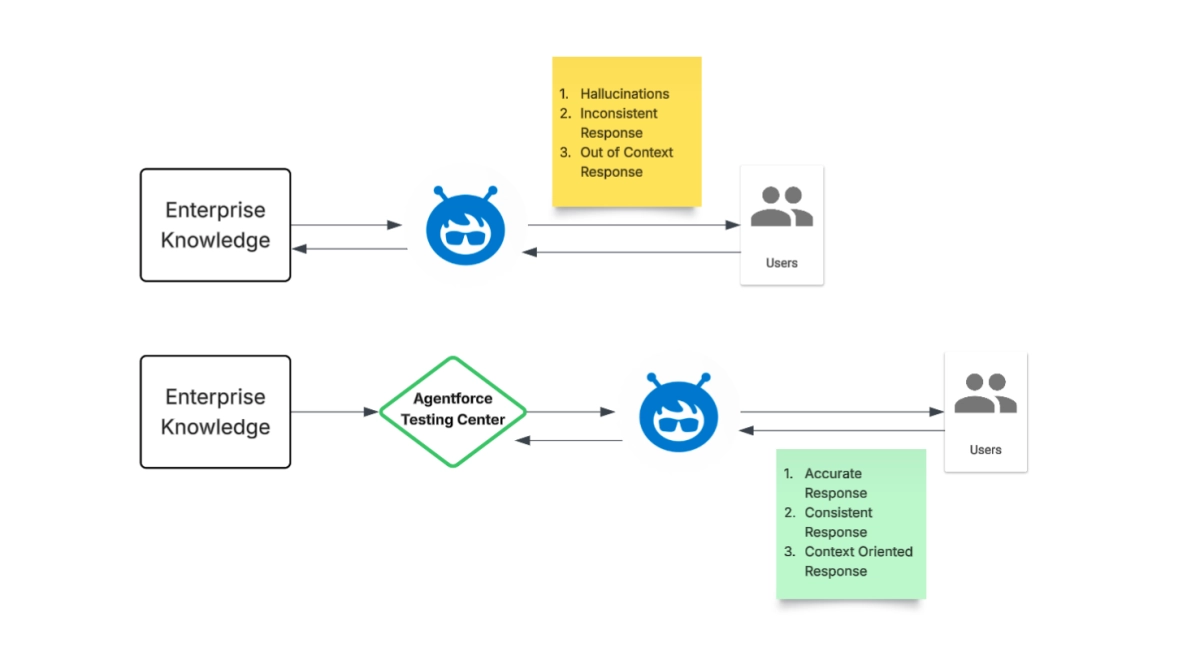
The rapid evolution of AI agents demands robust validation, a challenge Agentforce addresses with its new Testing Center. This platform offers a dedicated sandbox environment for rigorous offline AI agent evaluation, ensuring conversational AI systems deliver accurate, efficient, and reliable responses before deployment. This strategic move underscores a critical industry shift towards proactive quality assurance in AI development, mitigating risks and enhancing user trust from the outset.
The imperative for offline testing reflects a mature approach to AI lifecycle management, embracing the "shift left" principle common in traditional software engineering. By identifying and rectifying issues early, organizations can prevent knowledge gaps, inconsistent responses, and vulnerabilities to complex queries like prompt injection. Crucially, this controlled environment allows developers to catch agent hallucinations and failures to adapt to changing contexts, which are common pitfalls in real-world AI interactions. According to the announcement, this proactive evaluation saves significant time and resources while safeguarding reputational risk, a non-negotiable for enterprises deploying customer-facing AI.