As AI models balloon in complexity and parameter count, the era of general-purpose computing for cutting-edge machine learning is rapidly fading. Google is doubling down on specialized, co-designed hardware and software with its latest Tensor Processing Unit (TPU), Ironwood. Detailed by Distinguished Engineer Diwakar Gupta and Principal Engineer Manoj Krishnan, the Ironwood AI stack isn't just a new chip; it's a holistic supercomputing architecture built from the silicon up to power models like Gemini and Nano Banana.
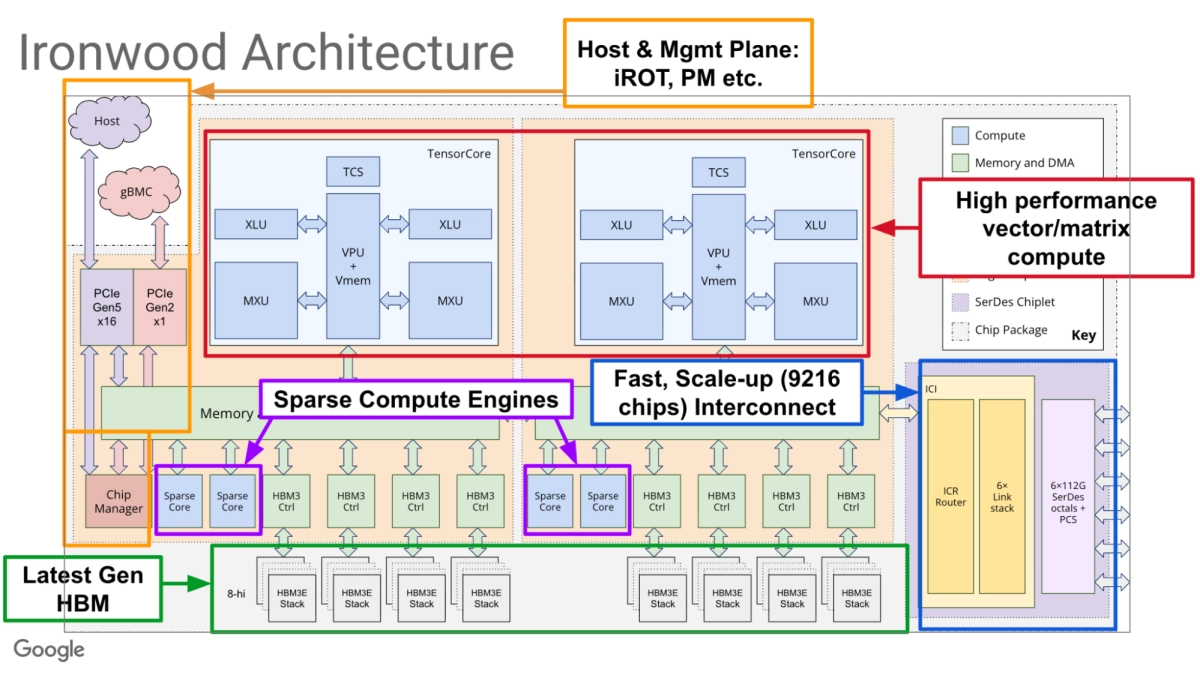
The core philosophy behind Ironwood is treating an entire TPU pod as a single, cohesive supercomputer, not merely a collection of accelerators. This starts with custom interconnects enabling massive-scale Remote Direct Memory Access (RDMA), allowing thousands of chips to exchange data directly at high bandwidth and low latency. Each Ironwood chip packs 192 GiB of HBM3E, contributing to a staggering 1.77 PB of directly accessible HBM capacity across a superpod. The hardware itself is an Application-Specific Integrated Circuit (ASIC), featuring a dense Matrix Multiply Unit (MXU) for core operations, a Vector Processing Unit (VPU) for element-wise tasks, and SparseCores for embedding lookups, collectively delivering 42.5 Exaflops of FP8 compute.