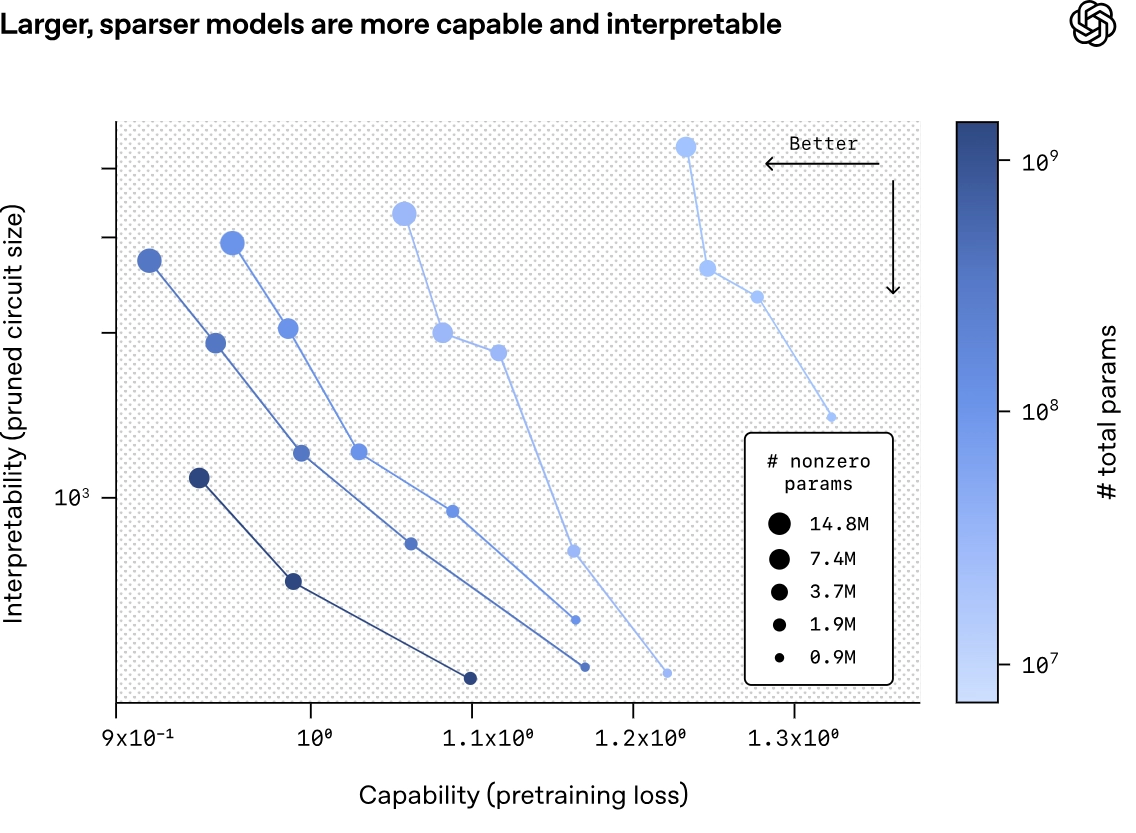
Neural networks are the engine of modern AI, but their dense, billions-of-parameters architecture makes them inscrutable. We design the training rules, but the resulting behavior is a tangled mess of connections no human can easily trace. This opacity is a growing liability as AI infiltrates critical sectors like healthcare and finance.
Interpretability, the ability to explain why a model made a decision, is paramount. While techniques like Chain of Thought offer immediate, albeit brittle, explanations by forcing models to show their work, the deeper goal is mechanistic interpretability: reverse-engineering the model’s computations at the most granular level. This path is harder but promises a more robust understanding.