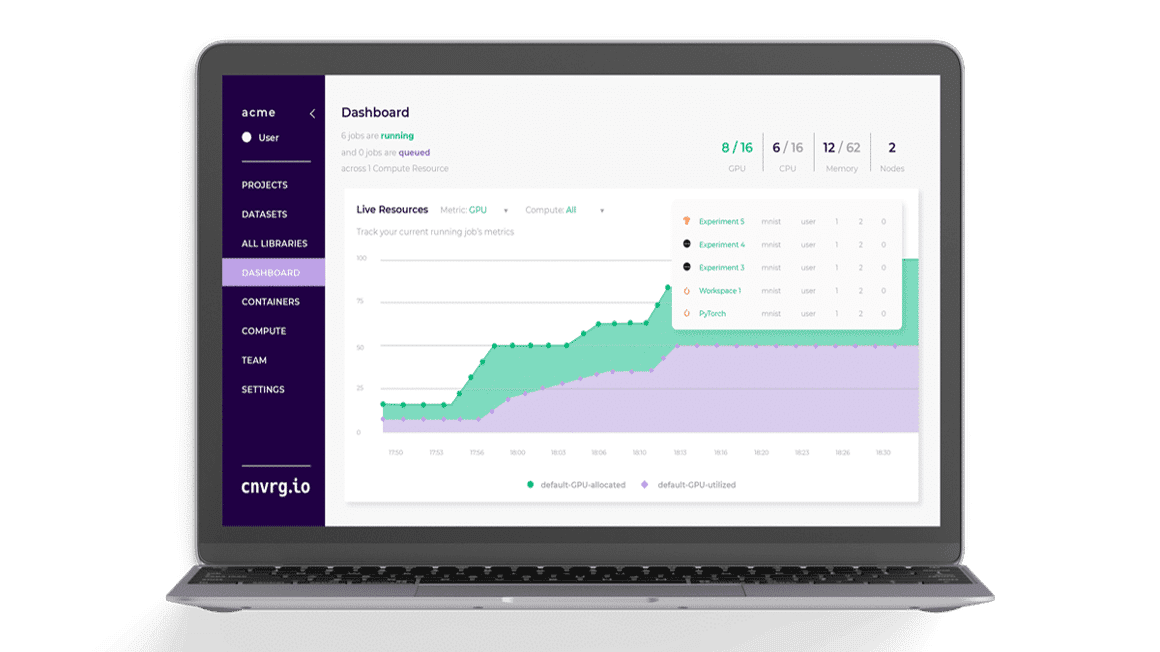
cnvrg.io AI OS for machine learning, today releases the MLOps Dashboard to its set of capabilities for advanced resource management of ML workloads. The solution fills a major gap in the industry, causing low ROI and the under-utilization of compute for ML. The end-to-end data science platform will now offer greater visibility of resource allocation, capacity and utilization that has the potential to increase GPU/CPU and Memory utilization by 70%.
One of the leading factors obstructing the ROI for machine learning is the under-utilization of GPUs/CPUs or Memory. Companies invest millions of dollars on compute that has the potential to dramatically accelerate AI workloads and improve performance, but end up only utilizing 20% of these powerful resources. The gap between compute allocation and actual utilization is shocking, and can cost companies more than they realize. Machine learning and deep learning are very compute intensive and complex to manage, making this computational debt difficult to reduce. Many infrastructure teams lack visibility of GPUs/CPUs and memory utilization for ML jobs, and are rarely able to attribute a job to its utilization. Not only that, but a lack of visibility can disrupt productivity, by blocking underutilized GPUs from being used for another job. cnvrg.io has introduced the MLOps Dashboard to help infrastructure teams visualize allocation and utilization of different jobs, clusters, by user and by container.