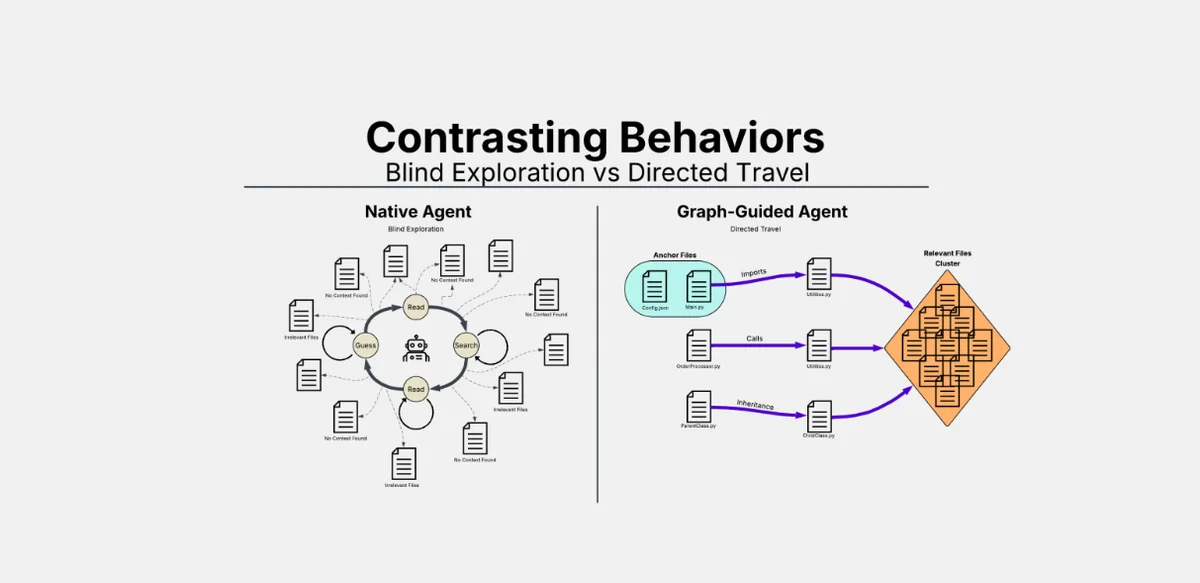
AI coding tools are outpacing human review capabilities, creating a critical bottleneck. New research from Causal Dynamics Lab (CDL) pinpoints the issue: AI agents spend disproportionate time searching for files rather than making edits. CDL's new product, Cielara Code, addresses this directly.
In independent tests, Cielara Code outperformed both Claude Code (Opus-4.6) and OpenAI Codex (GPT-5.4) in code localization accuracy.