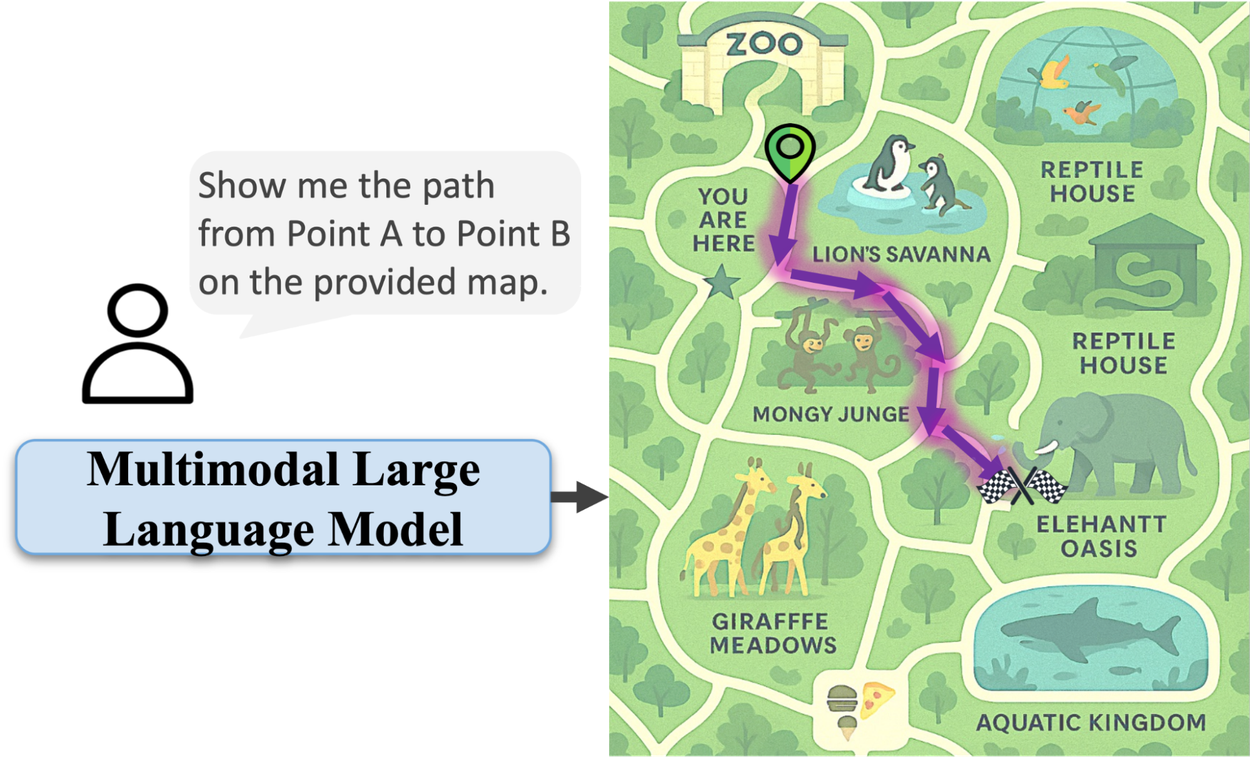
For all their impressive advances, AI models often falter when it comes to a seemingly simple human task: reading a map. While they can identify objects in an image, understanding the geometric and topological relationships needed to navigate from point A to point B remains a significant hurdle. This gap highlights a core limitation: AI excels at recognition but struggles with spatial reasoning.
The Map Navigation Challenge
Multimodal large language models (MLLMs) can identify a zoo, but tracing a path within it often proves difficult. They might draw lines through enclosures or gift shops, failing to grasp environmental constraints. This isn't a failure of vision, but a lack of understanding of how spaces connect and how movement is constrained.