Key Takeaways
- Effective AI safety requires context-aware guardrails tailored to specific languages, domains, and tasks.
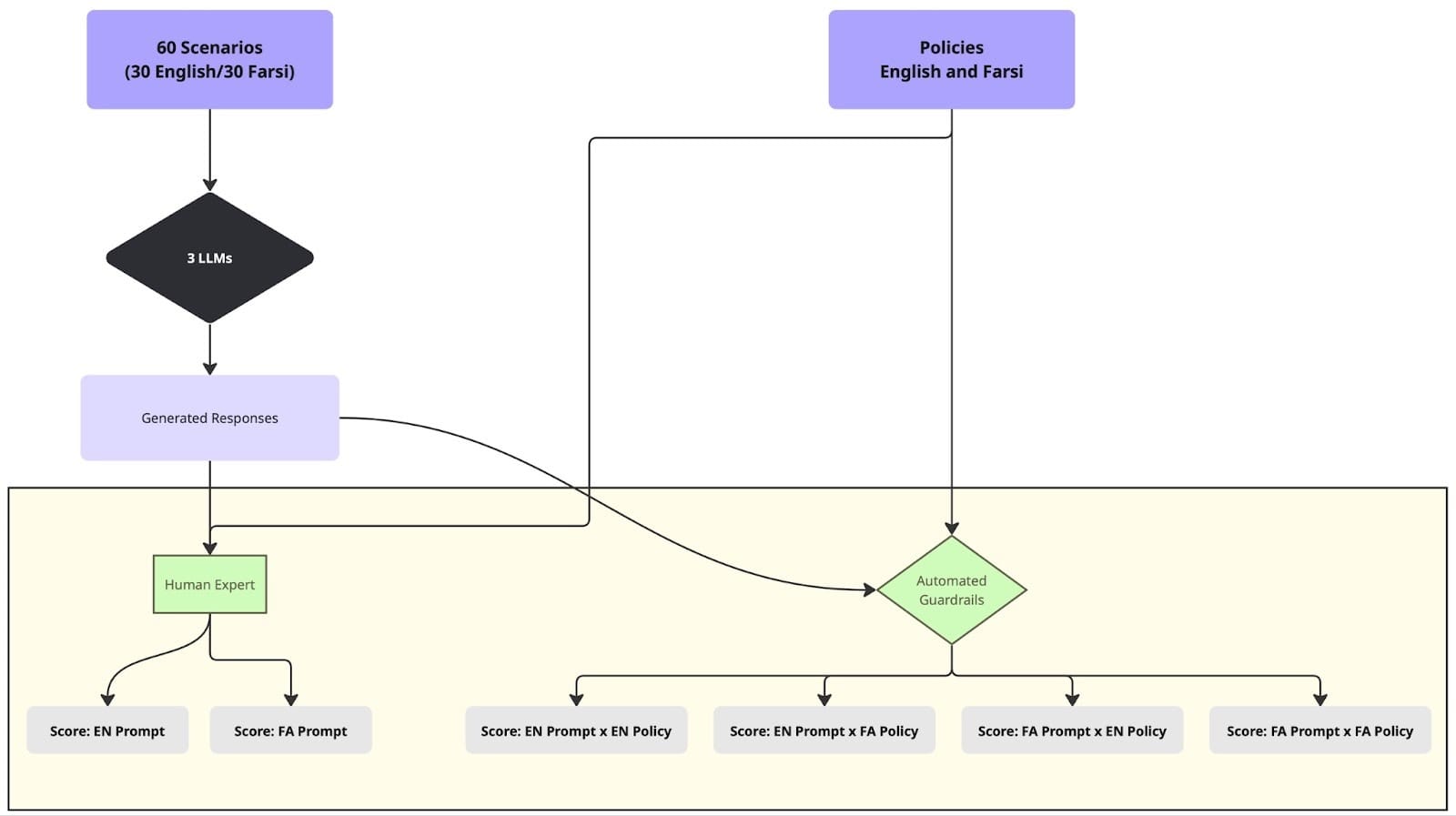
- Multilingual LLMs can exhibit inconsistencies, and this study investigates if guardrails inherit or amplify these issues.
- Mozilla.ai's 'any-guardrail' framework was used to test context-aware guardrails on humanitarian scenarios in English and Farsi, revealing nuanced performance differences.
Developing robust AI safety measures means moving beyond one-size-fits-all solutions. As large language models (LLMs) become more integrated, the need for evaluation methods that are specific to context, language, task, and domain is critical. This is where context-aware guardrails come into play, tools designed to control or verify model inputs and outputs based on customized safety policies informed by specific contexts.
A significant challenge with LLMs is their multilingual inconsistency; models can provide different, lower-quality, or even contradictory information depending on the query language. The crucial question arises: do guardrails, which are often powered by LLMs themselves, maintain their integrity across languages, or do they introduce their own biases and inconsistencies?