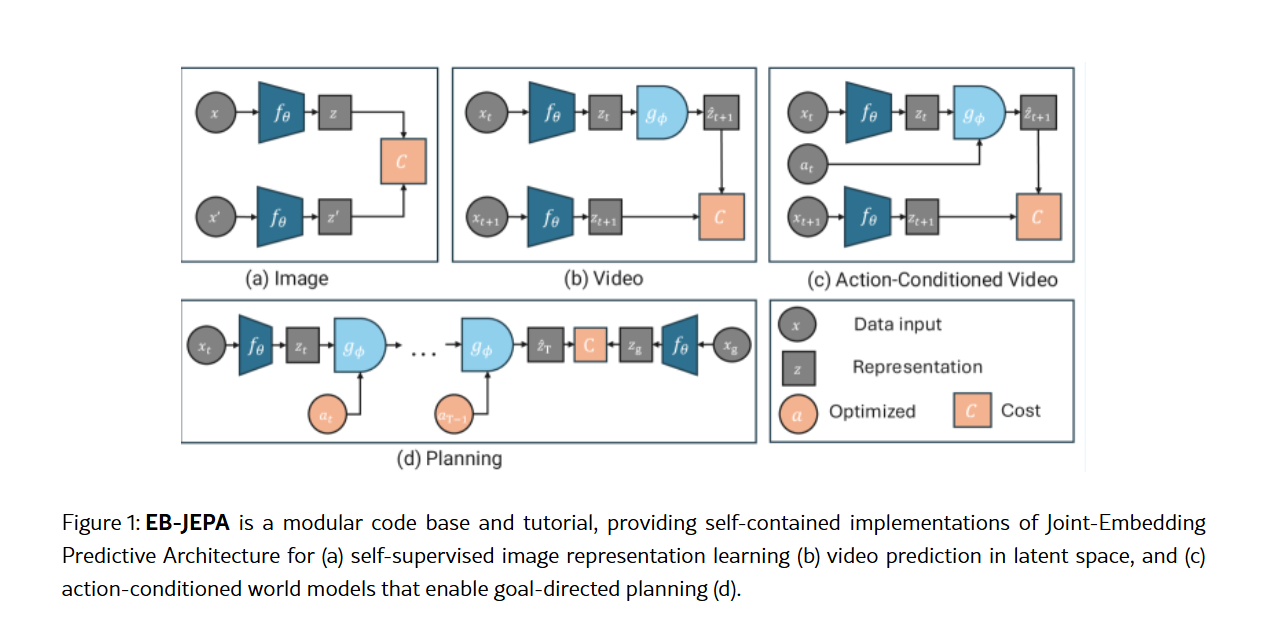
Meta AI researchers have released EB-JEPA, an open-source library designed to democratize the development of sophisticated AI world models. Built around Joint-Embedding Predictive Architectures (JEPAs), the library offers modular implementations for learning representations and predicting future states, moving beyond pixel-level reconstruction to focus on semantically meaningful features.
This new toolkit aims to lower the barrier to entry for researchers and educators, enabling complex self-supervised learning tasks on a single GPU within hours. The library covers three progressively challenging areas: image representation learning, video prediction, and action-conditioned planning.