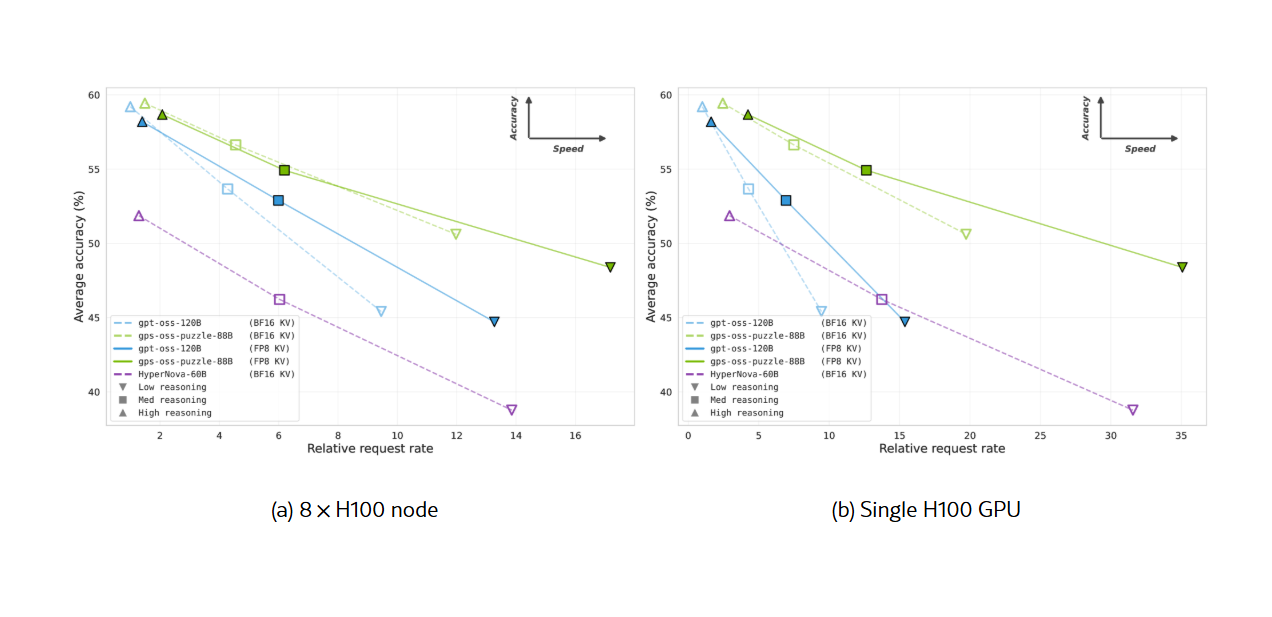
Serving large language models like GPT-OSS is a costly affair, especially when they're designed to generate lengthy reasoning traces for better answers. Now, researchers have developed a solution: gpt-oss-puzzle-88B, a derivative of the gpt-oss-120B model optimized for inference efficiency.
Cutting Down the Fat
The core challenge is balancing answer quality, which often requires more tokens, with the escalating costs of serving those tokens. The team behind gpt-oss-puzzle-88B applied a post-training neural architecture search framework called Puzzle to achieve this balance.