The AI coding assistant race has a dirty little secret: the smartest models are often painfully slow. While tools like Devin can perform marathon coding sessions, the initial, simple act of finding the right files in a codebase can take minutes, completely shattering a developer's focus. Cognition AI, the company behind Devin, is now tackling this "Semi-Async Valley of Death" head-on with a new approach called Fast Context Retrieval.
In a blog post published today, the company introduced SWE-grep and SWE-grep-mini, a pair of specialized models designed for one task: finding relevant code, fast. These models power a new subagent in their Windsurf IDE product called Fast Context, which Cognition claims can match the retrieval accuracy of frontier models in a tenth of the time.
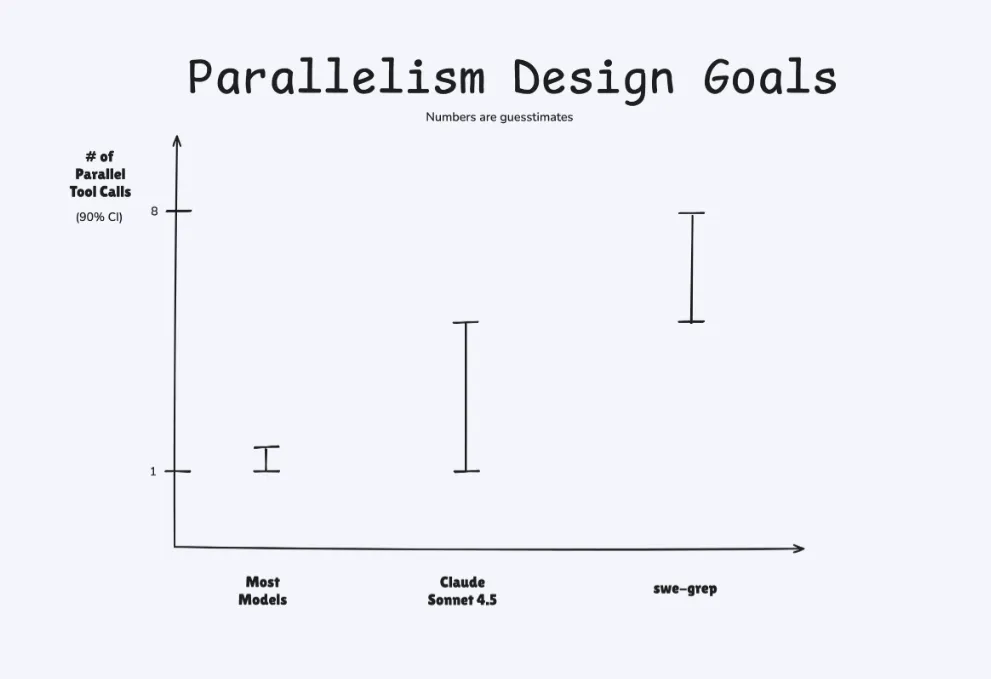
This isn't just about making things a little quicker. Cognition argues that the initial context-gathering phase can consume over 60% of an agent's first turn. This delay, they say, is where developers lose their "flow state," that elusive zone of deep concentration. Their stated goal is to keep agent interactions under a five-second "flow window."