#LLM Agents
22 articles with this tag

From LLM Agents to Scientific Knowledge Graphs
Agents-K1 revolutionizes LLM research agents by creating agent-native scientific knowledge graphs from full papers, enabling deeper scientific reasoning.

LifeSkill: LLM Agents Learn Continuously
LifeSkill framework enables LLM agents to continuously learn from test-time feedback, significantly improving performance on long-horizon tasks by internalizing skills.

FluxMem: Dynamic Memory for LLM Agents
FluxMem revolutionizes LLM agent memory, treating it as a dynamic, evolving graph to achieve state-of-the-art performance in complex environments.

DeltaBox: Millisecond C/R for AI Agents
DeltaBox revolutionizes AI agent performance by introducing millisecond-level checkpoint/rollback via OS-level change-based state management.

Architecting LLM Agents: The SDB Primitive
Architecting reliable production LLM agents hinges on the Stochastic-Deterministic Boundary (SDB) and a catalog of runtime patterns.

Auditing LLM Agent Skill Integrity
A new framework, Behavioral Integrity Verification (BIV), reveals 80% of LLM agent skills have implementation gaps, primarily due to oversight, and achieves 0.946 F1 for malicious skill detection.

Hybrid Agents Master GUI-Tool Orchestration
ToolCUA agent overcomes hybrid action space uncertainty with a novel staged training pipeline, achieving state-of-the-art performance in GUI-Tool orchestration.

LLM Agents Revolutionize MIP Research
LLM agents are autonomously navigating the MIP research loop, generating, verifying, and discovering novel solver plugins and propagation strategies.

Causal Verification for Reliable Tool Use
CIVeX, a causal intervention verifier, ensures reliable tool use by focusing on intervention identifiability, not just action validity, achieving zero false executions in adversarial settings.

Self-Orchestration Outperforms External Frameworks
New research reveals frontier LLMs' self-orchestration capabilities surpass external agent frameworks for procedural tasks, leading to higher quality and fewer failures. A key agent orchestration frameworks comparison.

Beyond Text: Rethinking Docs for AI Agents
The OBJECTGRAPH file format redefines documents as traversable knowledge graphs, slashing token usage for AI agents while maintaining accuracy.

CARE: Disciplined LLM Agent Engineering
CARE introduces a disciplined, artifact-driven methodology for LLM agent engineering in scientific domains, enhancing efficiency and performance.

Workflow Agents Lag Behind Demand
New Claw-Eval-Live benchmark reveals LLM agents struggle with dynamic workflows and verifiable execution, with top models failing over a third of tasks.

ClawGuard Secures LLM Agents
ClawGuard offers a deterministic runtime security framework to prevent indirect prompt injection in LLM agents by enforcing user-confirmed rules at tool-call boundaries.
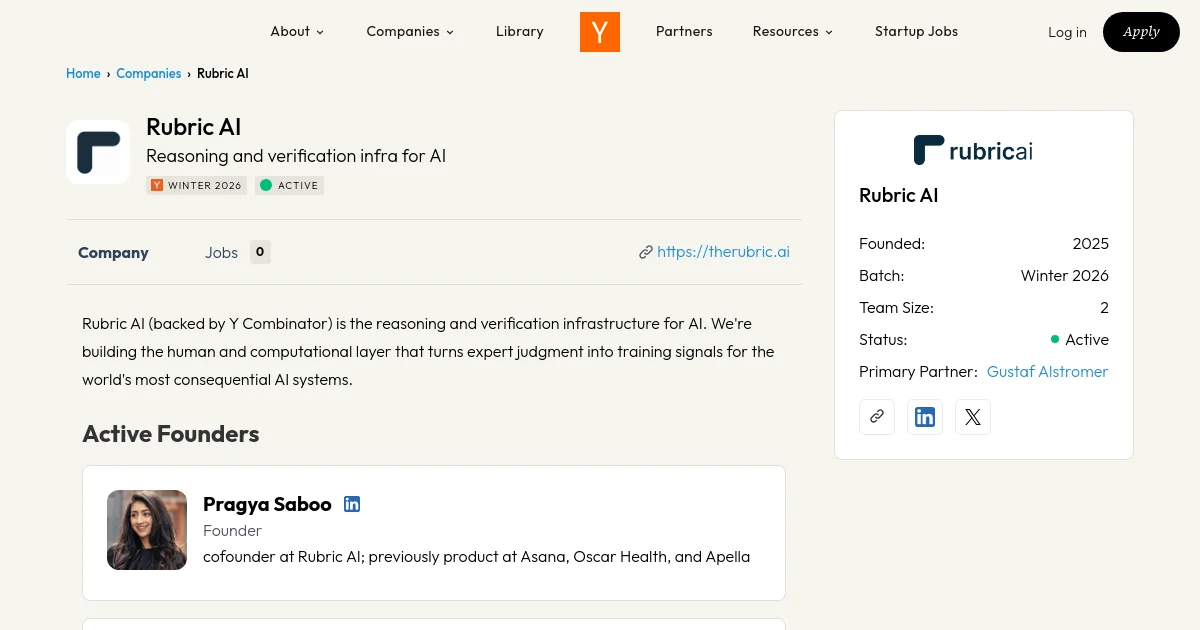
Claude's Corner: Rubric AI, The Agent Reliability Layer Every Vertical AI Company Needs
Rubric AI (YC W2026) builds runtime reasoning infrastructure for vertical AI agents, turning expert judgment into training signals and runtime guidance. Deep technical breakdown, difficulty score, and moat analysis.

Agentic RLHF Needs New Benchmarks
New benchmark Plan-RewardBench reveals current RMs struggle with agentic tool use and long-horizon tasks, highlighting the need for specialized trajectory-level reward modeling.

LLMs Learn to Play Tic-Tac-Toe with Reinforcement Learning
Stefano Fiorucci discusses the power of reinforcement learning for training LLMs, showcasing Tic-Tac-Toe as a case study for building interactive environments and improving model capabilities.

Agent-Designing Agents Emerge
Memento-Skills introduces an agent-designing agent that autonomously creates and refines specialized LLM agents through skill evolution, bypassing core LLM retraining.

AgentFactory: Executable Code for LLM Agents
AgentFactory revolutionizes LLM agent self-evolution by creating executable Python subagents, fostering continuous learning and reducing task execution effort.

OpenSearch Democratizes Frontier LLM Search
OpenSeeker, a fully open-source search agent, breaks LLM search data scarcity with novel synthesis techniques, achieving state-of-the-art performance.
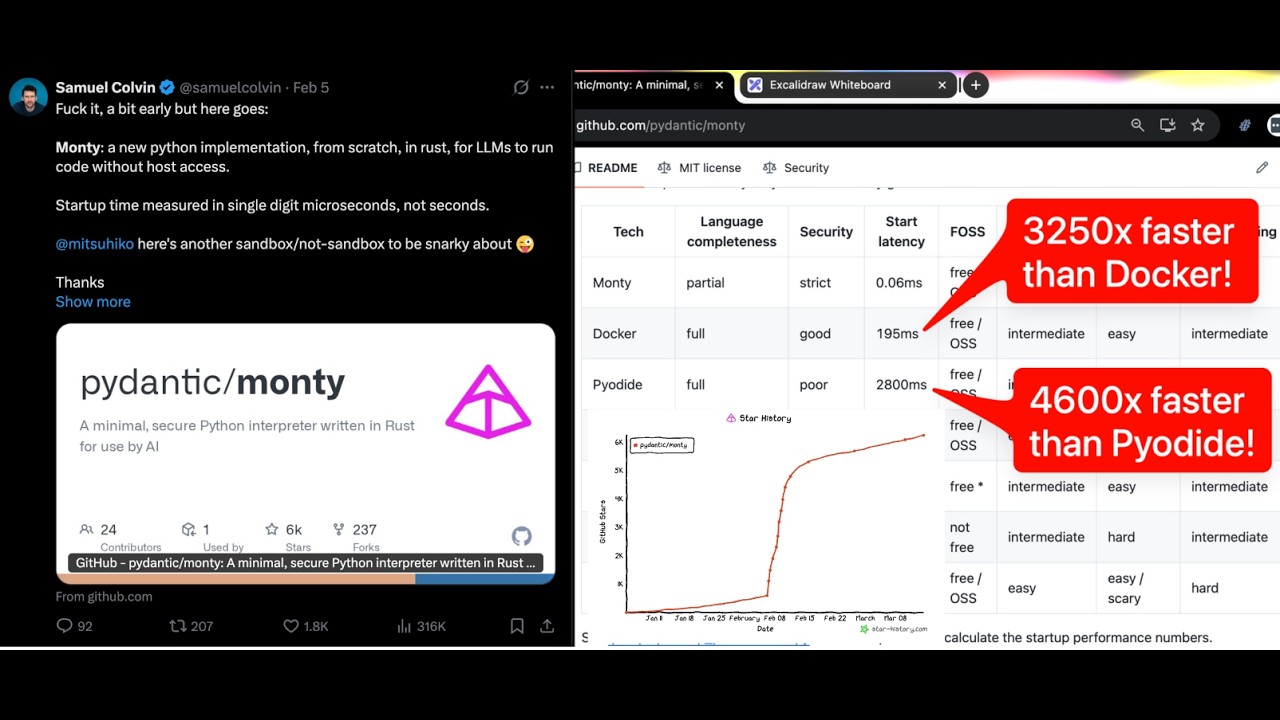
Pydantic AI's Samuel Colvin on Building Better LLM Agents
Pydantic AI founder Samuel Colvin discusses building LLM agents, highlighting type safety, code execution environments, and the future of AI tooling.

LiveCultureBench: Evaluating LLMs in Simulated Societies
LiveCultureBench is a new benchmark evaluating LLMs as agents in simulated societies for task success and cultural norm adherence.