The shift from AI search to AI agents embedded directly in the browser opens a massive new attack surface. As assistants move from simply answering questions to actively performing tasks across authenticated sessions, email, banking, enterprise apps, the risk of prompt injection escalates dramatically. Malicious actors can now hide instructions in the messy, high-entropy content of real web pages to hijack agent behavior.
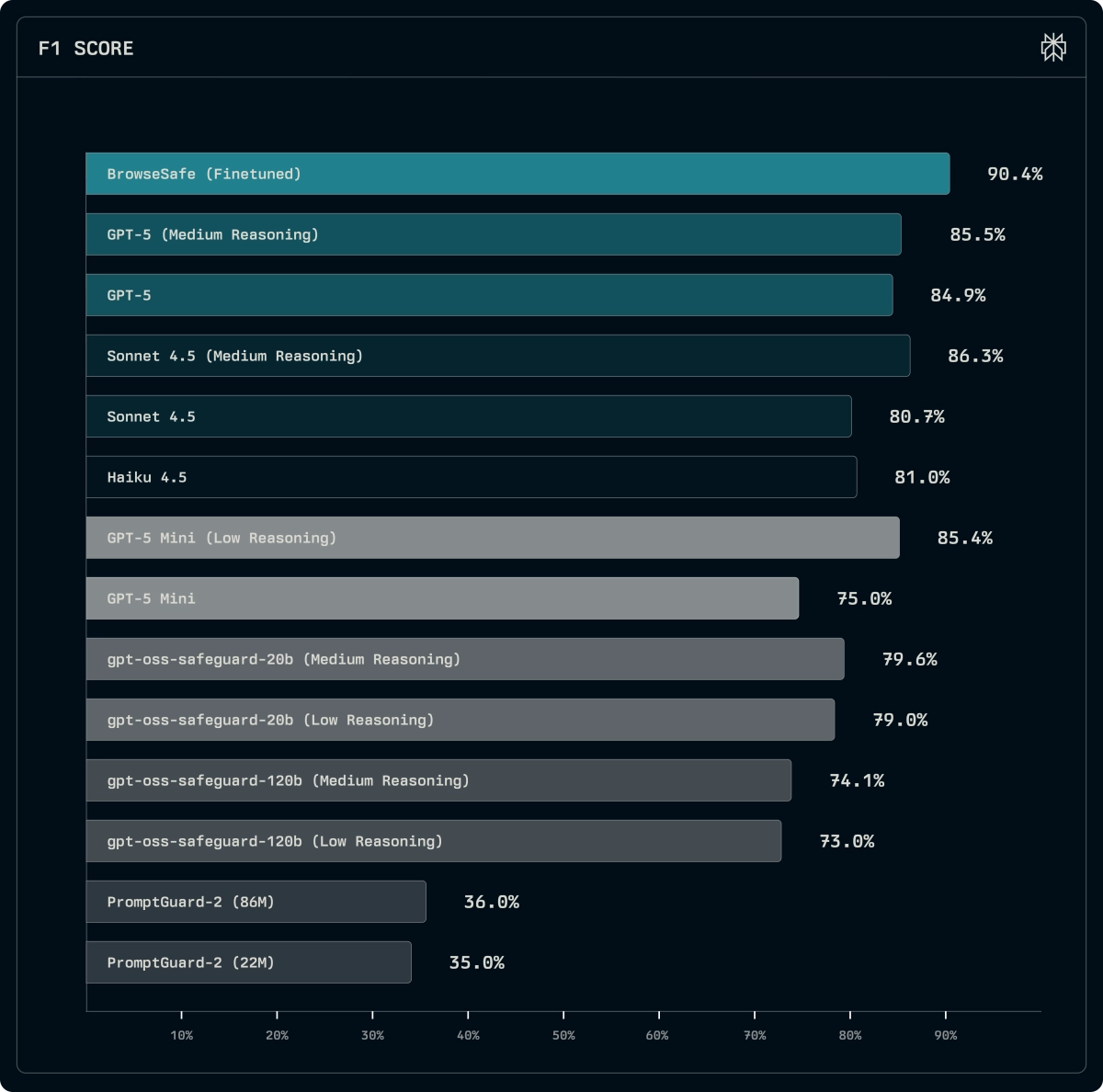
In response, researchers have released BrowseSafe, an open research benchmark and a specialized content detection model designed specifically for this new "agentic web." This work, stemming from development on the Comet browser agent, directly addresses the shortcomings of existing security evaluations which often rely on simple, short adversarial text rather than the complex HTML environments agents actually navigate.