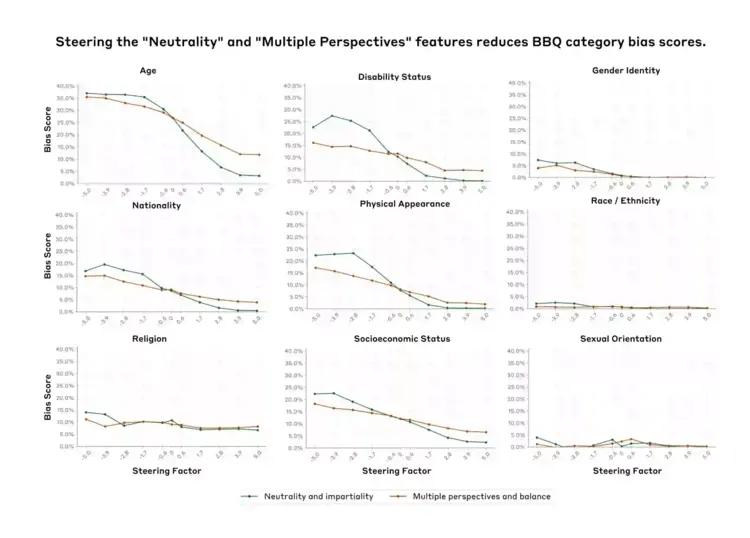
Anthropic recently unveiled a significant study titled "Evaluating Feature Steering: A Case Study in Mitigating Social Biases". The study explores the nuanced use of feature steering in Claude 3 Sonnet, the company's latest language model, aiming to understand whether this technique can effectively mitigate social biases without compromising the model's overall capabilities.
The research builds on Anthropic's previous interpretability work, demonstrating their ability to identify and manipulate specific interpretable features of the model. The new experiments examine whether feature steering, a method that adjusts the influence of individual model features by modifying its internal state, can reliably mitigate social biases without affecting the model's other capabilities.