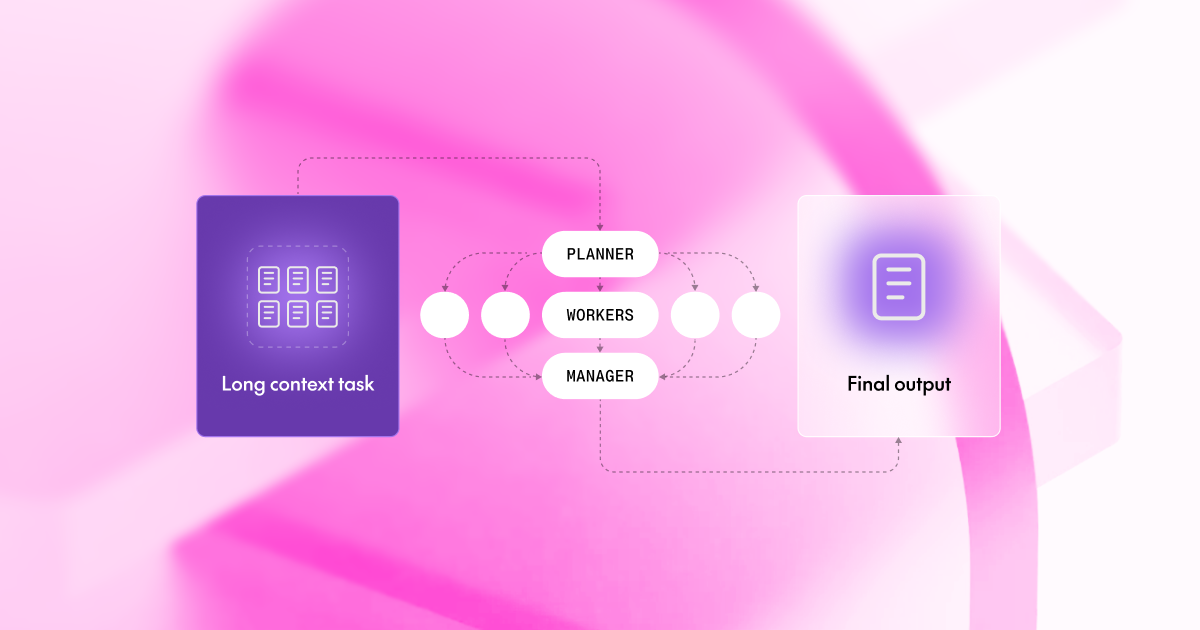
Forget asking a single AI genius to digest an entire library. A new research paper from Together AI proposes a smarter method: assemble an army of less powerful interns. This "divide and conquer" strategy, detailed in their work "When Does Divide and Conquer Work for Long Context LLM?", demonstrates how smaller, more cost-effective language models can achieve or even surpass the performance of giants like GPT-4o on tasks requiring extensive context.
The core idea is to tackle the inherent limitations of modern LLMs when faced with massive context windows, which often lead to performance degradation. The research identifies three primary sources of 'noise': Model Noise (where models become overwhelmed), Task Noise (where splitting a task breaks crucial dependencies), and Aggregator Noise (where the final summary is flawed). By addressing these through a structured framework involving a Planner, Workers, and a Manager, the approach aims to mitigate these issues.