Anthropic just dropped a deep dive into how they're tackling Claude political bias, and they’re putting their money where their mouth is: open-sourcing their new automated evaluation method. The company claims its latest models, particularly Claude Sonnet 4.5, exhibit superior political even-handedness compared to rivals like GPT-5 and Llama 4 when measured by their "Paired Prompts" system.
This isn't just another internal benchmark. Anthropic is pushing for industry standardization, arguing that shared metrics for measuring political neutrality are essential for building trustworthy AI. Their methodology pits models against thousands of prompts covering hundreds of political stances, grading responses on even-handedness, inclusion of opposing perspectives, and refusal rates.
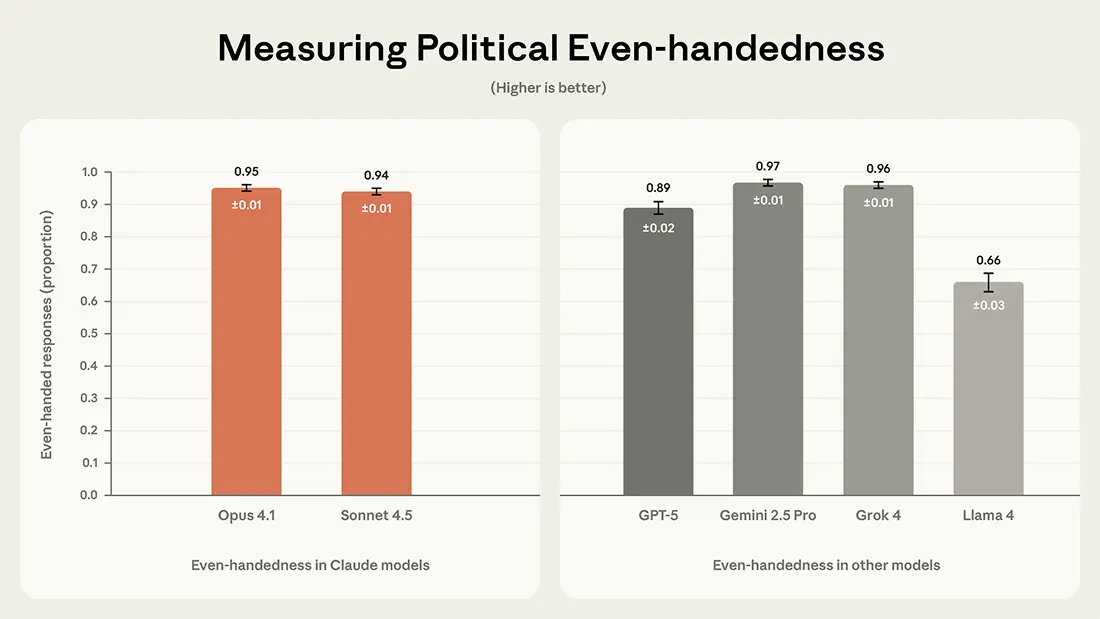
The Even-Handed Showdown
The results position Claude Sonnet 4.5 (94%) and Opus 4.1 (95%) neck-and-neck with Google’s Gemini 2.5 Pro (97%) and xAI’s Grok 4 (96%). OpenAI’s GPT-5 lagged noticeably at 89%, while Meta’s Llama 4 scored a concerning 66% on even-handedness. Furthermore, Anthropic’s models reportedly showed strong performance in acknowledging counterarguments, a key indicator of balanced engagement.
What’s particularly interesting is the validation process. Anthropic used other leading models, including GPT-5, as automated graders for a subset of tests, finding high correlation with their primary Claude grader. This suggests that, at least by this specific metric, the results aren't just self-serving echo chamber data.
However, the report is careful to list caveats. The evaluation heavily favors current US political discourse, ignores international contexts, and focuses only on single-turn interactions—a significant limitation in real-world use. While Anthropic is training Claude with specific character traits designed to promote objectivity—like refusing to generate propaganda or take partisan stances—the industry still lacks a universal consensus on what "ideal" political neutrality looks like. By open-sourcing the evaluation, Anthropic is inviting scrutiny, but the core challenge remains: defining and consistently achieving fairness in an inherently subjective domain. This move forces competitors to either adopt or publicly refute this new standard for measuring Claude political bias.


