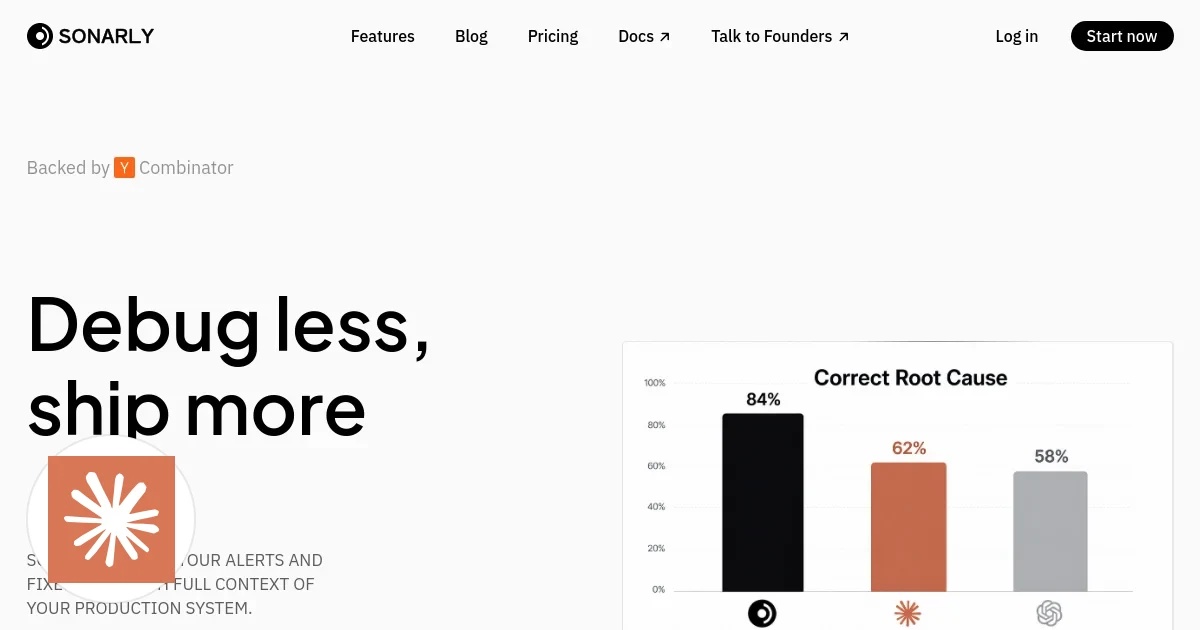
At 3 AM, an alert fires. Your on-call engineer silences it, squints at Datadog for twenty minutes, follows five different threads across Sentry, Slack, and a GitHub blame log, and eventually, maybe, traces it to a bad deploy. Then they write a fix, open a PR, and drag themselves back to bed. The whole thing took 90 minutes and cost them tomorrow's productivity.
Sonarly thinks this is insane, and they're right.