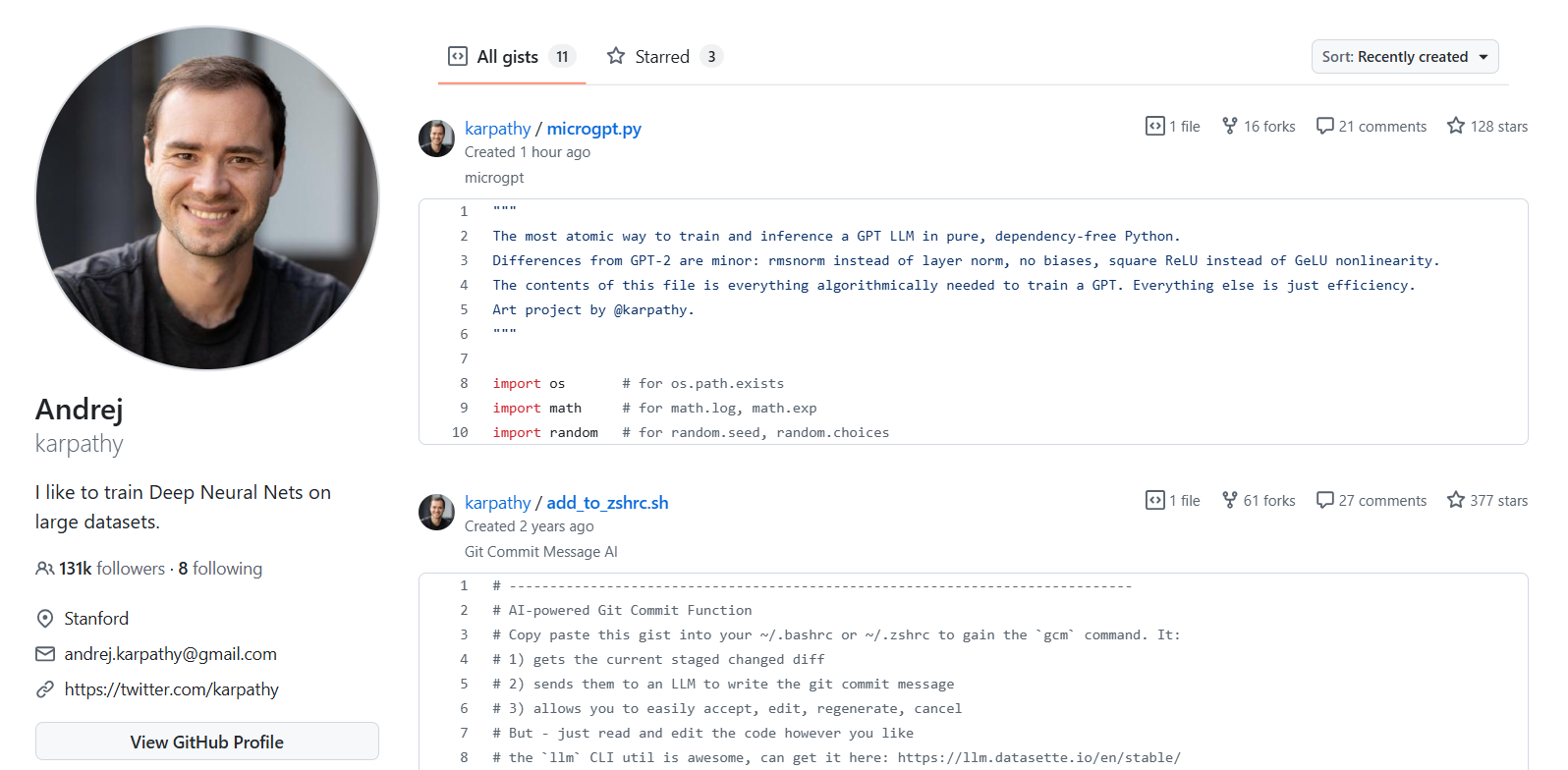
Andrej Karpathy, a prominent figure in AI research and former director of AI at Tesla, has unveiled what he calls microGPT. This project is a remarkably compact implementation of a GPT-like large language model, written entirely in pure, dependency-free Python.
Described by Karpathy as an "art project," microGPT is designed to distill the essential algorithmic components required to train and run a Transformer-based language model. It intentionally omits efficiency optimizations and framework abstractions, focusing solely on the core mechanics.