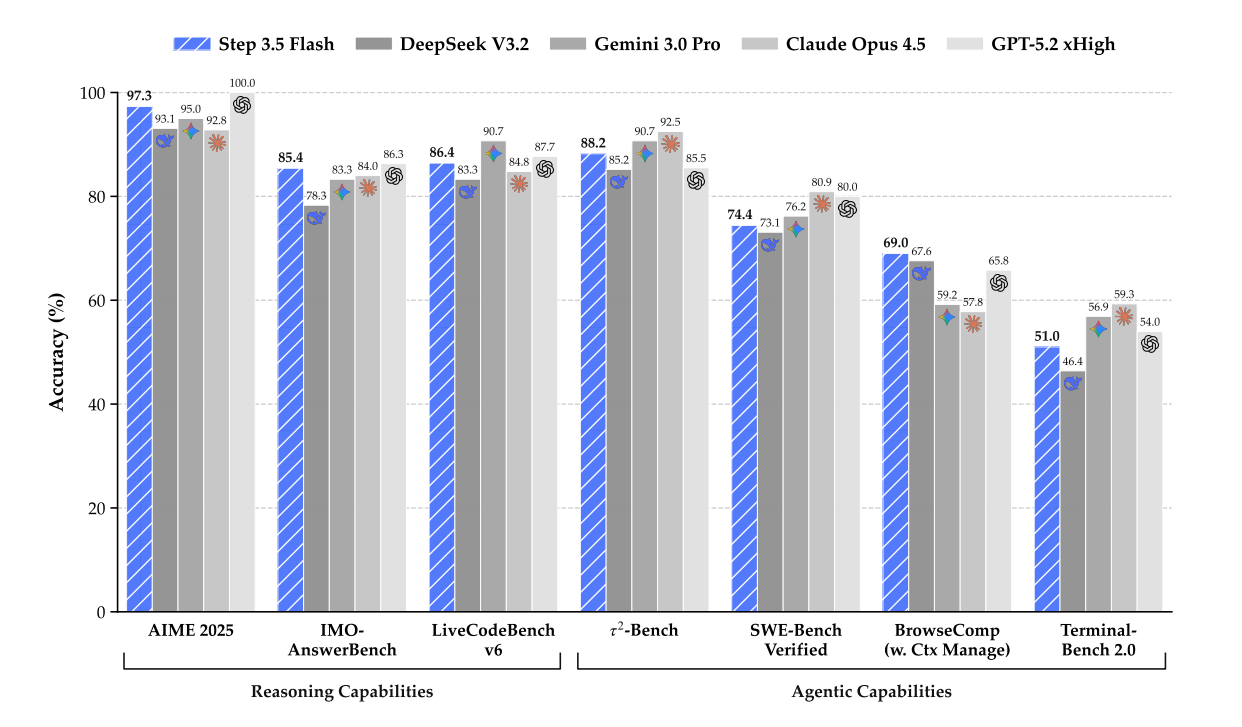
The AI race for raw reasoning power has hit a practical limit. Users demand frontier-level intelligence, the kind that tackles complex math problems, but not at the cost of minutes-long waits or exorbitant API fees. Enter Step 3.5 Flash, a new model from the StepFun Team designed to bridge this gap.
Intelligence Density Over Brute Force
Step 3.5 Flash operates on a principle of "High-Density Intelligence." It pairs a massive 196 billion parameter foundation with a highly efficient 11 billion active parameter execution engine. This architecture allows it to compete with models like GPT-5.2 xHigh and Gemini 3.0 Pro while maintaining agility.