Arcee.ai has unveiled its Trinity family of open-weight Mixture-of-Experts (MoE) language models, highlighted by the flagship Arcee Trinity Large. This new generation of LLMs emphasizes inference-time efficiency and long-context capabilities, targeting enterprise deployments with a focus on auditability and data provenance.
Trinity Models: Scale and Efficiency
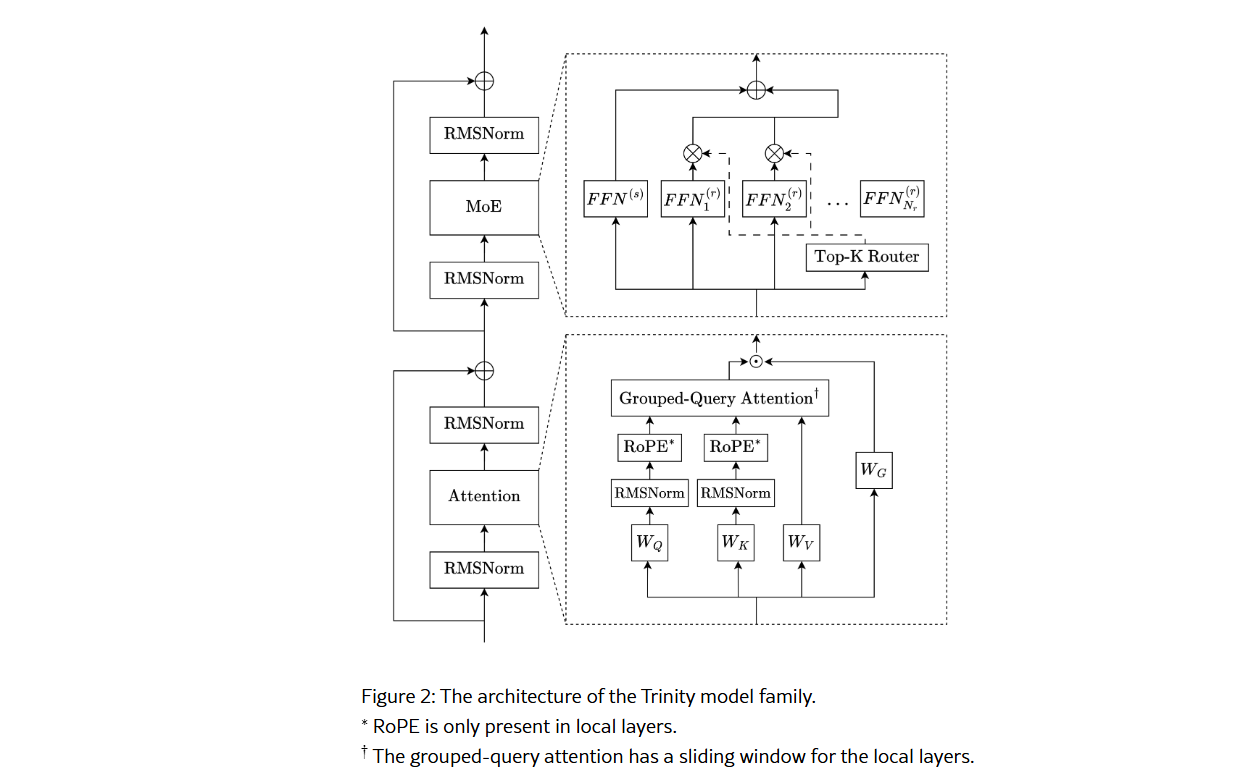
The Trinity lineup includes Trinity Nano (6B total parameters, 1B activated per token), Trinity Mini (26B total, 3B activated), and the formidable Trinity Large (400B total, 13B activated). These models feature a modern architecture that combines interleaved local and global attention, gated attention, and a depth-scaled sandwich norm. All models were trained using the Muon optimizer, achieving zero loss spikes throughout their extensive pre-training.
Trinity Nano and Mini processed 10 trillion tokens, while Trinity Large was pre-trained on an impressive 17 trillion tokens. Arcee.ai has made the model checkpoints publicly available on Hugging Face, underscoring their commitment to open-weight foundations.