The shift from AI search to AI agents embedded directly in the browser opens a massive new attack surface. As assistants move from simply answering questions to actively performing tasks across authenticated sessions—email, banking, enterprise apps—the risk of prompt injection escalates dramatically. Malicious actors can now hide instructions in the messy, high-entropy content of real web pages to hijack agent behavior.
In response, researchers have released BrowseSafe, an open research benchmark and a specialized content detection model designed specifically for this new "agentic web." This work, stemming from development on the Comet browser agent, directly addresses the shortcomings of existing security evaluations which often rely on simple, short adversarial text rather than the complex HTML environments agents actually navigate.
The Messy Reality of Browser Prompt Injection Defense
Prompt injection, the technique of embedding malicious language to override an AI’s core instructions, becomes far more insidious when the AI is reading an entire webpage. Unlike conversational interfaces where attacks are often direct, browser agents parse everything: comments, hidden data attributes, form fields that never render visually, and sprawling footers. Attackers exploit this by slipping instructions into content most users never see, or by camouflaging them in polished, multilingual text that bypasses simpler keyword detectors.
The core challenge BrowseSafe tackles is speed versus accuracy. Large, general-purpose LLMs can reason through complex injection attempts, but they introduce unacceptable latency—seconds per page—which bottlenecks the responsiveness users expect from a browser assistant.
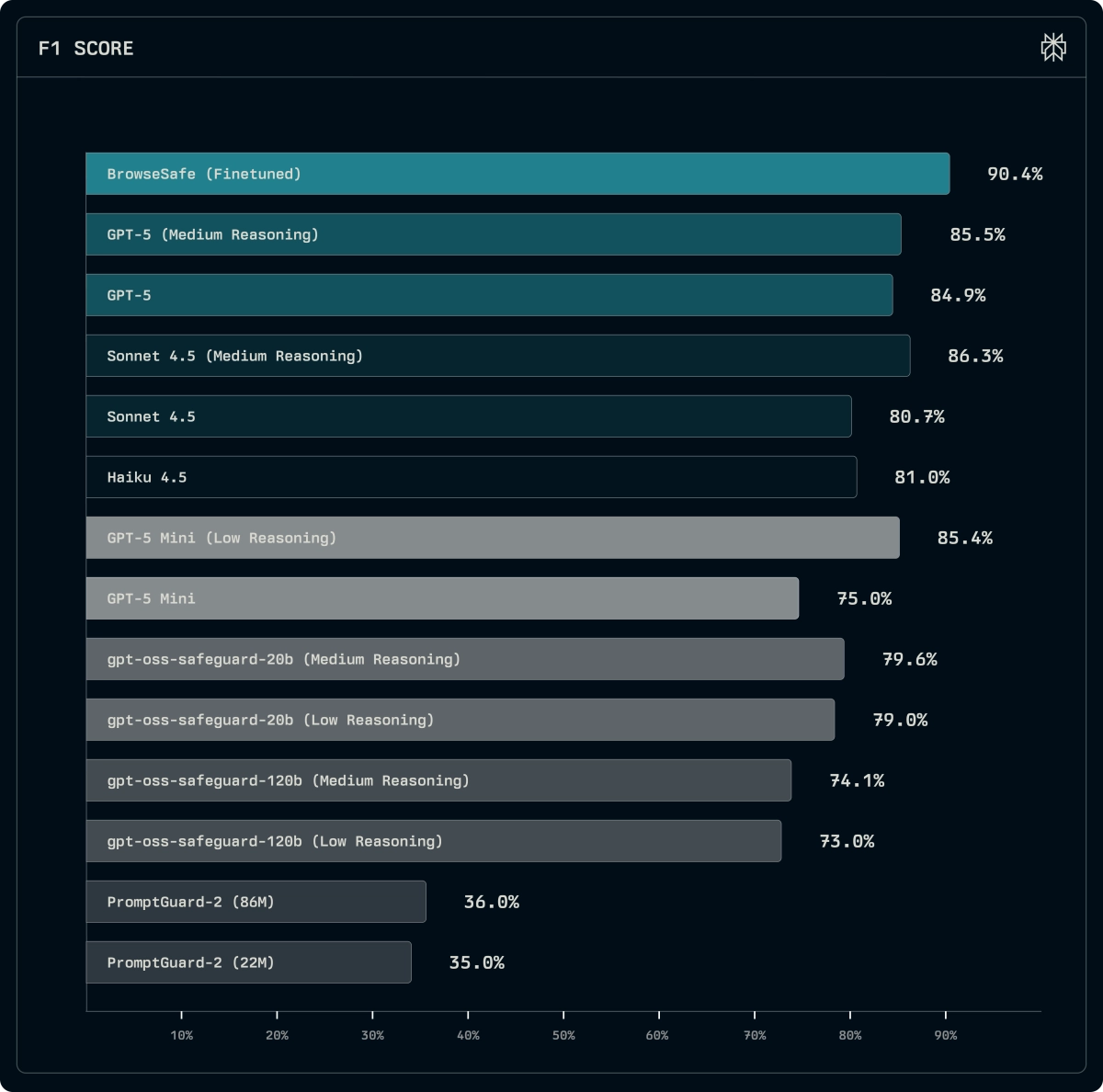
To solve this, the team developed BrowseSafe, a detection model fine-tuned specifically to scan HTML for malicious intent in real-time. This model is built to run fast enough to scan every page without slowing the user down, sacrificing some out-of-domain generalization for superior in-domain performance against real-world threats.
To rigorously test and advance prompt injection defense, they also released BrowseSafe-Bench, a public benchmark comprising 14,719 synthetic examples mimicking production pages. This suite is crucial because it breaks down attacks across three axes: the attacker’s objective (Attack Type), the payload placement (Injection Strategy), and the phrasing sophistication (Linguistic Style).
Initial evaluations on BrowseSafe-Bench reveal clear patterns in attack effectiveness. The easiest attacks to catch are the direct ones—asking the agent to reveal its system prompt or exfiltrate data via obvious commands. The hardest threats are those that employ linguistic camouflage, such as indirect or hypothetical instructions, and those embedded in visible page elements like footers or inline paragraphs. Attacks hidden in comments or metadata were surprisingly easier to detect, suggesting a structural bias in current models toward flagging "hidden" injections over those that blend into visible content.
Furthermore, noise matters. The introduction of benign but complex "distractor" elements—text that looks command-like but isn't malicious—significantly degraded detection accuracy across models, indicating that many detectors rely on brittle correlations rather than true intent understanding.
The proposed security architecture emphasizes defense in depth. The web content itself is treated as inherently untrusted. BrowseSafe acts as the first line of defense, scanning raw content before the agent processes it. This fast classifier is supplemented by a hybrid approach: uncertain cases are escalated to slower, more powerful frontier LLMs for deeper reasoning, creating a backstop against novel attacks. This layered system pairs the detector with architectural guardrails like limited tool permissions and mandatory user confirmation for sensitive actions.
By open-sourcing both the BrowseSafe model and the BrowseSafe-Bench dataset, the developers are pushing the industry toward standardized, realistic testing for agent security. For any developer building autonomous agents that interact with the open web, this benchmark provides an immediate tool to stress-test defenses against the messy HTML traps that break standard LLMs. The goal is clear: enable powerful, agentic browsing capabilities without forcing users to trade safety for functionality. This work signals a necessary pivot in AI security, moving from securing conversational endpoints to hardening the entire web interaction layer.