#LLM Inference
9 articles with this tag

Together AI Masters MiniMax M3 Inference
Together AI details engineering feats enabling efficient MiniMax M3 inference, unlocking 1M-token context and multimodality.

Together AI Supercharges LLM Inference
Together AI unveils ATLAS, accelerating LLM inference up to 4x with adaptive speculative decoding, tackling the growing cost challenge for AI-native companies.

Together AI's Aurora Learns on the Fly
Together AI's Aurora framework uses RL to continuously adapt speculative decoding for faster LLM inference, outperforming static models.

Mamba-3: Inference-First SSMs Arrive
Together AI's Mamba-3 advances state space models with a focus on inference speed, outperforming previous versions and some Transformers.
NVIDIA Nemotron 3 Nano launches on FriendliAI
The race to serve the next generation of efficient, open AI agents is heating up, and FriendliAI is aggressively positioning itself as the crucial infrastruc...

NVIDIA Nemotron 3 Nano launches on FriendliAI
The race to serve the next generation of efficient, open AI agents is heating up, and FriendliAI is aggressively positioning itself as the crucial infrastruc...
Clarifai Hits Fastest GPT-OSS-120B Inference and Narrows the GPU, ASIC Gap
Clarifai’s latest benchmark on OpenAI’s GPT-OSS-120B model points to a quiet but important shift in AI infrastructure.
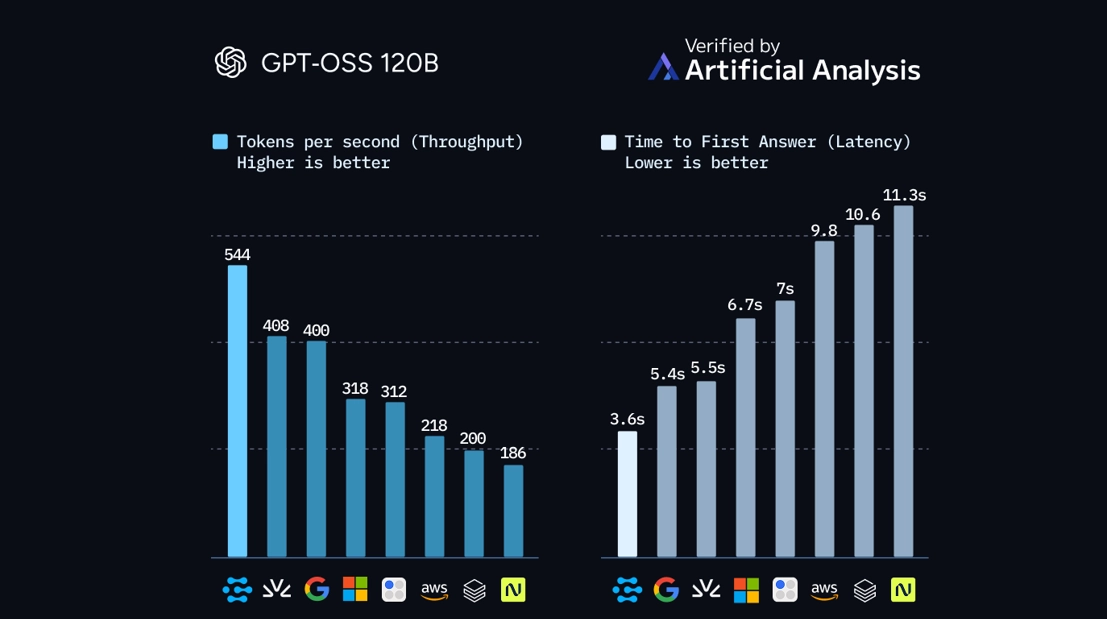
Clarifai Hits Fastest GPT-OSS-120B Inference and Narrows the GPU, ASIC Gap
Clarifai’s latest benchmark on OpenAI’s GPT-OSS-120B model points to a quiet but important shift in AI infrastructure.