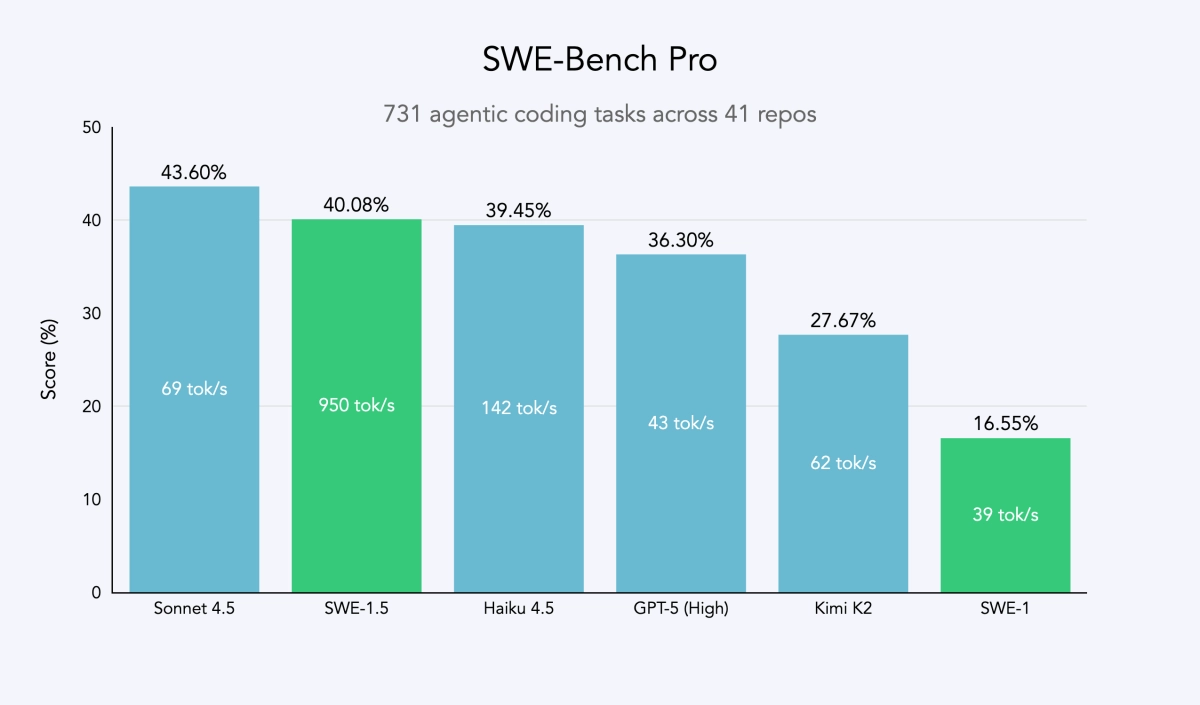
The race for the best AI coding assistant has often forced a difficult choice on developers: do you want a model that’s fast, or one that’s smart? A new company, spun out of the team behind the Devin agent, claims its new SWE-1.5 model finally eliminates that tradeoff. In a blog post, the team announced that SWE-1.5, a "frontier-size model with hundreds of billions of parameters," achieves near state-of-the-art coding performance while setting a new benchmark for speed.
Partnering with inference provider Cerebras, the company says it can serve the SWE-1.5 model at up to 950 tokens per second. To put that in perspective, they claim it's 13 times faster than Anthropic's Sonnet 4.5 and 6 times faster than Haiku 4.5. For a developer, that’s the difference between an AI completing a task in 20 seconds versus under five, a crucial margin that keeps them in the "flow state."