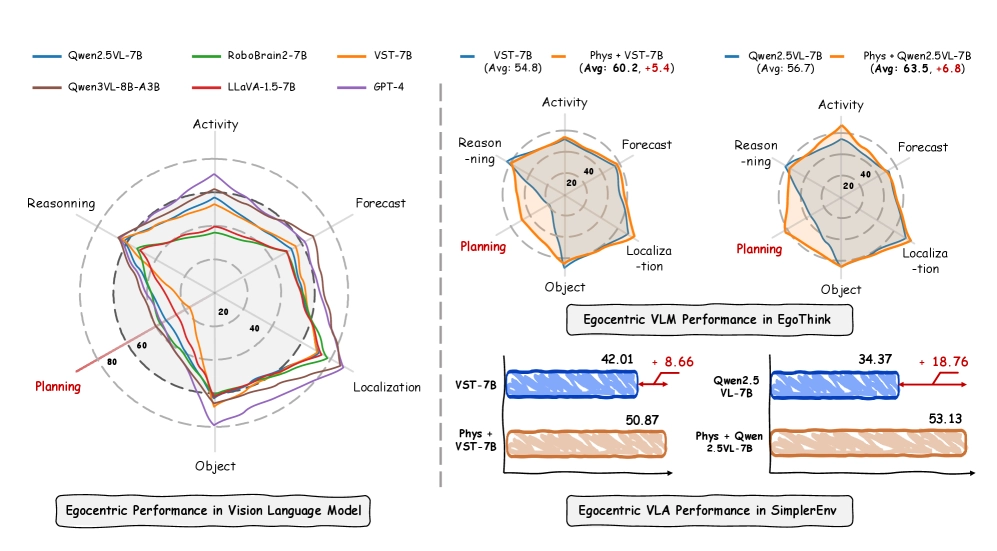
The fundamental bottleneck in building physically intelligent robots has long been the data. Vision Language Models (VLMs) are typically trained on vast troves of third-person video, creating a critical viewpoint mismatch when applied to a humanoid robot operating with a head-mounted, first-person (egocentric) camera. Collecting enough high-quality, diverse robot data to fix this gap is prohibitively expensive.
Now, a team of researchers has proposed a scalable solution: the PhysBrain model, an egocentric-aware embodied brain trained almost entirely on structured human video.