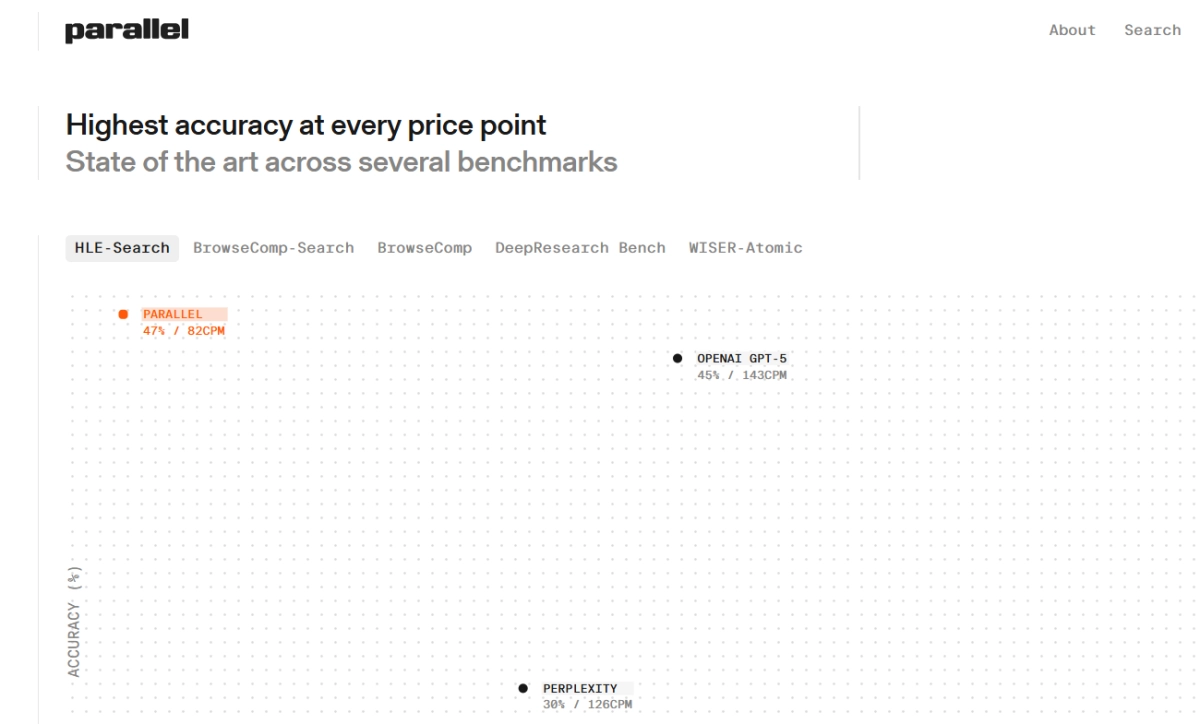
The internet, as we know it, was built for humans. Its search engines, designed for clicks and page views, have long served our browsing habits. But a new user has arrived, one with fundamentally different needs: artificial intelligence. This week, Parallel.ai officially launched its Parallel Search API, a web search tool engineered from the ground up to serve AI agents, promising higher accuracy and dramatically lower costs for complex tasks.
Traditional search engines, like Google, optimize for keywords and user engagement, delivering a list of URLs for a human to sift through. The system's job ends at the link. But for an AI agent, clicking through and navigating pages is inefficient. What an AI needs isn't a link, but the precise, relevant tokens of information to feed into its context window for reasoning. This distinction, Parallel argues, is where existing web search APIs, often adapted from human-centric models, fall short.