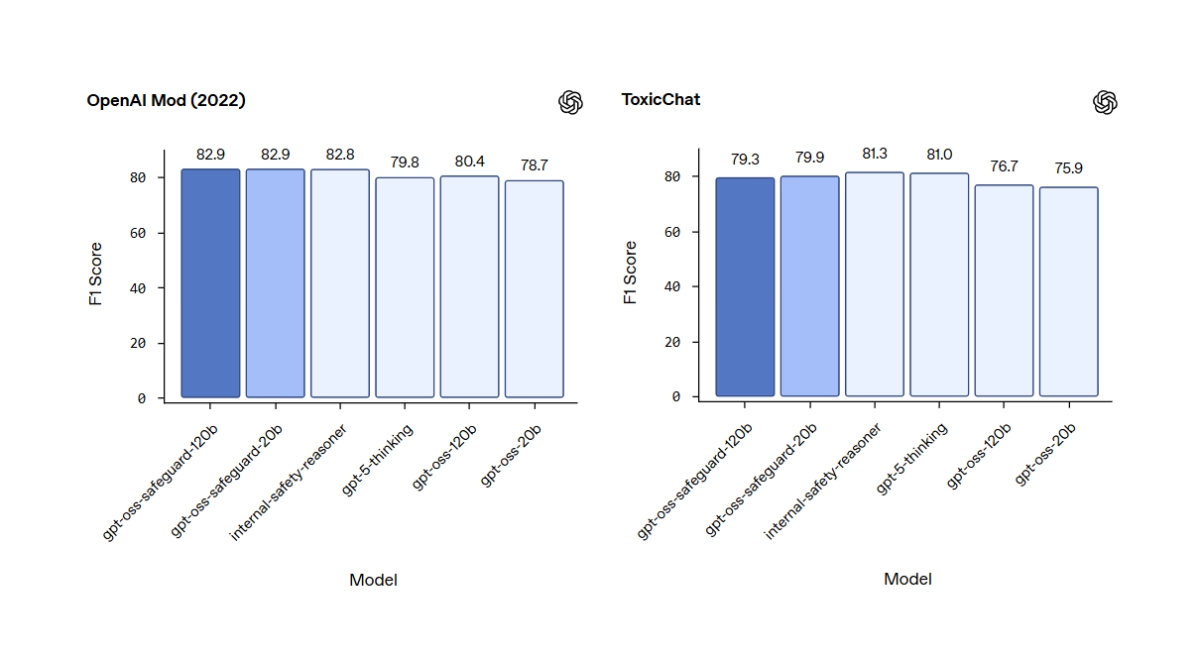
OpenAI just dropped a pair of open-source models that could fundamentally change how developers handle content moderation. The new models, dubbed gpt-oss-safeguard, aren’t your typical safety classifiers. Instead of being a black box trained on a mountain of pre-labeled data, they’re designed to reason based on a custom safety policy you write yourself.
Available on Hugging Face in 120-billion and 20-billion parameter sizes, gpt-oss-safeguard operates on a simple but powerful premise. A developer feeds the model two things at once: the content they want to check (a user comment, a full chat log, etc.) and a specific policy (e.g., “No posts that reveal spoilers for the latest season of *House of the Dragon*”). The model then uses a chain-of-thought process to reason about whether the content violates that specific rule, outputting not just a yes/no decision but also its rationale.