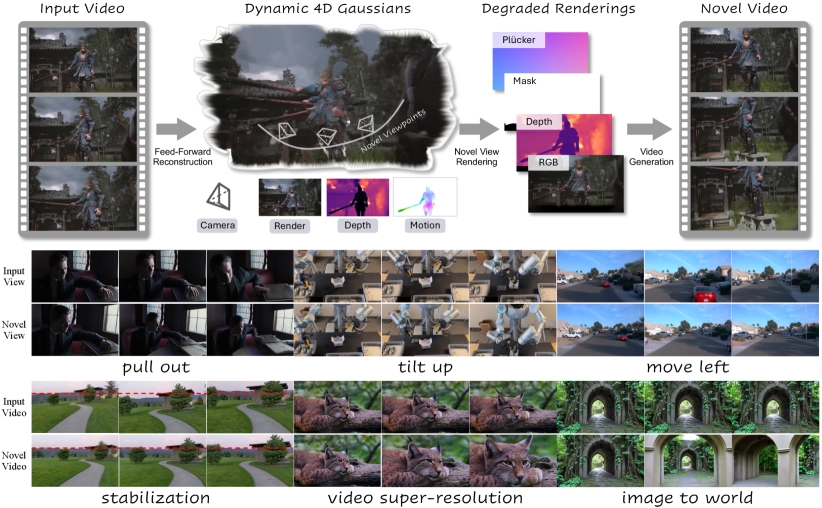
The promise of 4D world modeling, creating dynamic, editable digital twins of real-world scenes, has long been hampered by a fundamental bottleneck: data. Building high-fidelity 4D models typically requires specialized, multi-view camera setups or cumbersome, offline pre-processing stages, severely limiting the ability of these systems to generalize beyond curated lab environments.
A new paper from researchers at CASIA and CreateAI, titled NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos, proposes a solution that fundamentally shifts the paradigm. NeoVerse is a versatile monocular 4D model designed to leverage the cheapest and most abundant data source available: in-the-wild monocular videos.