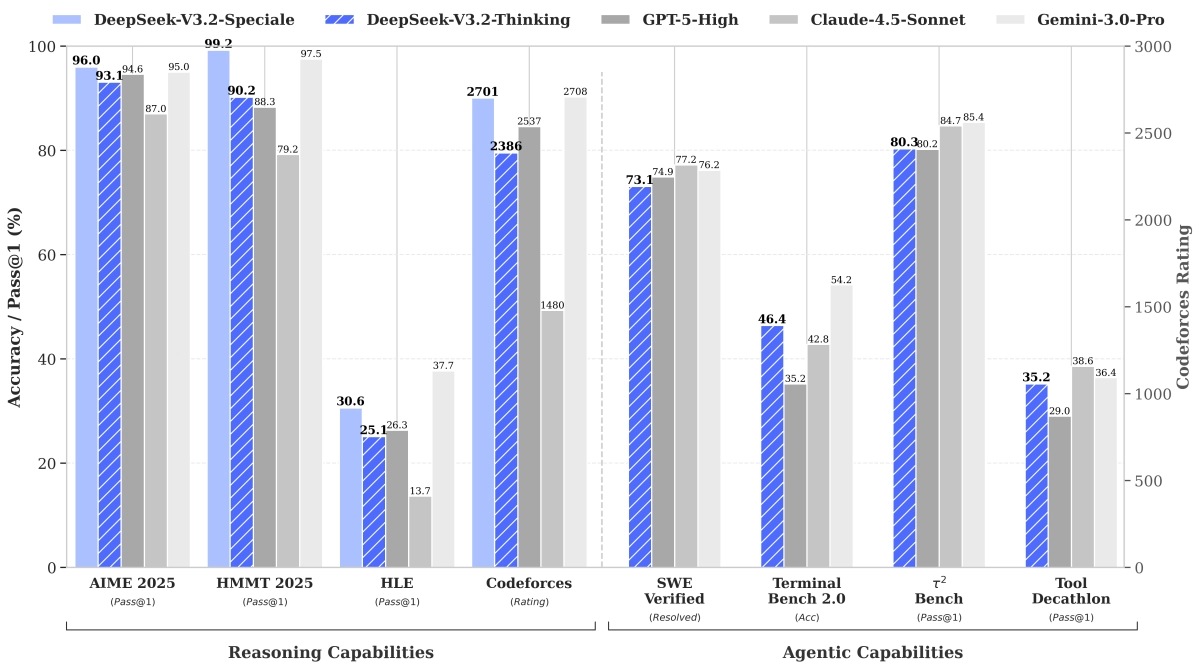
The DeepSeek V3.2 release signals a significant push in the open-source LLM race, not just chasing raw benchmark scores but specifically targeting agentic capabilities and complex reasoning. DeepSeek AI has dropped two variants: the general-purpose V3.2, claimed to hit GPT-5 level performance, and the powerhouse V3.2-Speciale, which they position against Gemini 3.0 Pro, even showcasing gold medal results in simulated 2025 Olympiads (IMO, IOI).
The technical report highlights three core innovations. First, DeepSeek Sparse Attention (DSA) tackles the long-context efficiency problem, moving attention complexity from quadratic to near-linear, a crucial step for real-world agent deployment where context windows balloon. Second, a massive, synthetically generated agent training dataset, 1,800 environments and 85,000 instructions, underpins the new focus on tool-use.