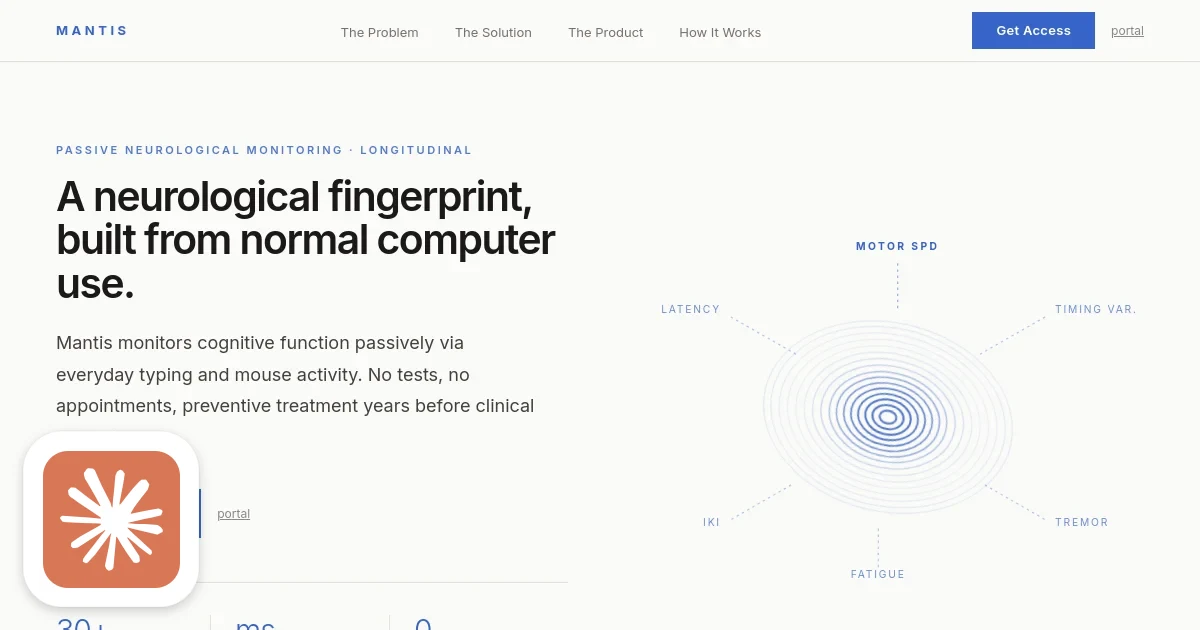
The dirty secret of AI in biomedicine is that it runs on borrowed time. Every drug discovery model, every surgical robotics system, every injury-prediction algorithm is only as good as its training data, and biomedical training data is either locked behind HIPAA walls, physically impossible to collect at scale, or simply doesn't exist yet. You can't run 10,000 variations of a knee surgery on real patients. You can't record every possible injury mechanism across every body type. You can't get labeled MRI datasets for rare diseases because by definition, very few people have them.
Mantis Biotech (YC W26) thinks physics is the answer. Not more crowdsourcing. Not more synthetic generation from a diffusion model that's memorized what training data looks like. Actual physics simulation, the kind that respects Newton's laws, muscle fiber mechanics, fluid dynamics, and the biochemical constraints of the human body, combined with LLMs to process the messy real-world signals that feed the simulation.