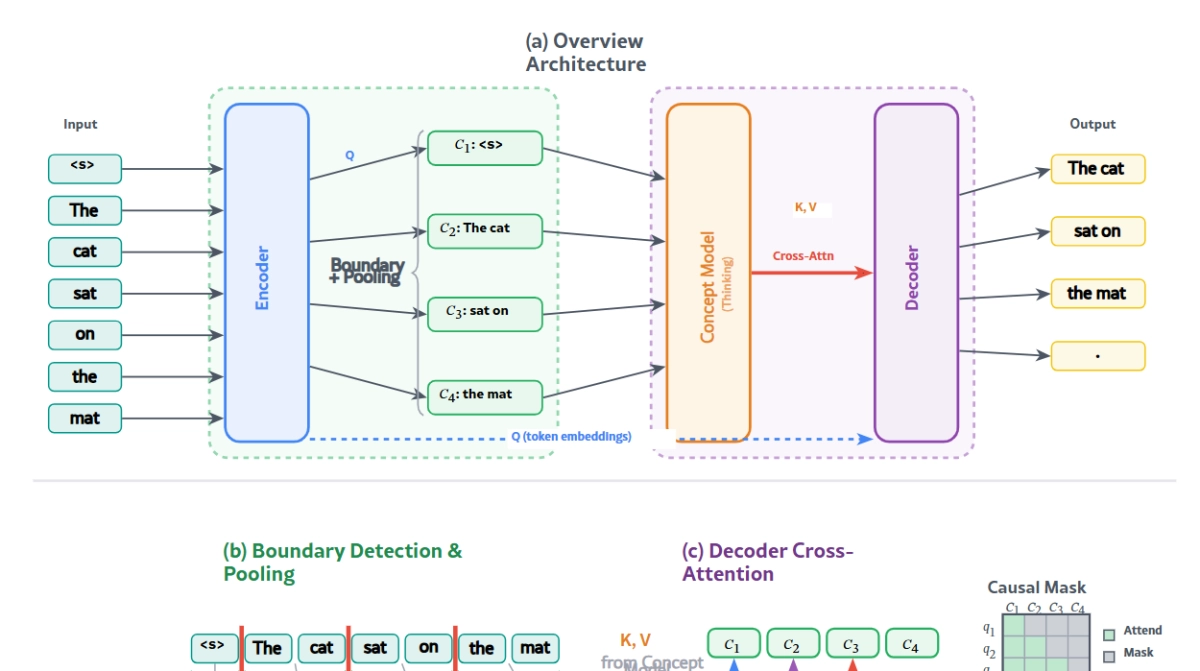
The transition from the era of brute-force scaling to a more nuanced regime of inference-optimal architecture is perhaps best exemplified by the emergence of Dynamic Large Concept Models, or DLCM. For several years, the artificial intelligence industry has operated under what many researchers call the token tax, a fundamental inefficiency where standard transformer architectures allocate the same amount of computational power to every single token regardless of its complexity or information density. Whether a model is processing a highly predictable function word like the or a semantically dense transition in a logical proof, the depth and floating-point operations applied remain identical. This compute-blind approach ignores the reality that language is inherently non-uniform, with long spans of predictable text interspersed with sparse but critical transitions where new ideas are introduced. By challenging this token-uniform paradigm, DLCM introduces a hierarchical framework that effectively separates the process of identifying what to think about from the actual process of reasoning, marking a significant milestone in the development of more efficient and capable large language models.
At the core of the DLCM framework is a four-stage pipeline designed to mirror the abstract way in which humans actually process information. Unlike standard models that treat text as a flat stream of individual tokens, DLCM begins with a lightweight causal transformer encoder that extracts fine-grained representations of the raw input. These representations then feed into a dynamic segmentation mechanism, often referred to as a global parser, which identifies semantic boundaries directly from the latent space rather than relying on rigid linguistic rules or punctuation. Once these variable-length segments or concepts are identified, the model performs deep reasoning within a compressed concept space using a high-capacity transformer backbone. Finally, a decoder reconstructs the specific token predictions by attending to these enriched concept representations through a causal cross-attention mechanism. This design allows the model to shift its computational resources away from redundant token-level processing and toward high-level semantic reasoning, ensuring that the majority of inference effort is spent on the parts of the sequence that actually require it.