
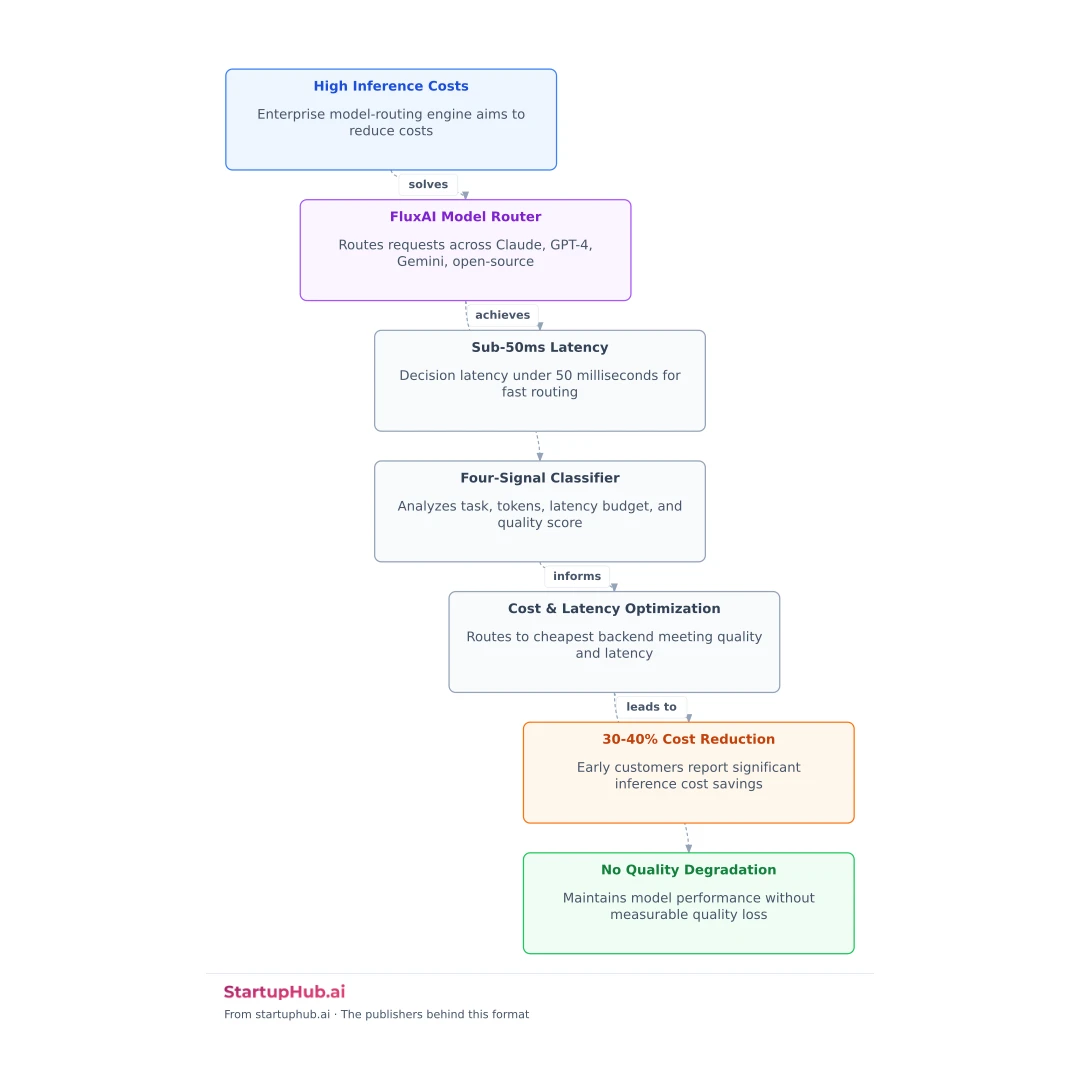
FluxAI today announced the general availability of its enterprise model-routing engine, a control plane that distributes inference requests across Claude, GPT-4, Gemini, and self-hosted open-source models in under 50 milliseconds.
The platform sits in front of existing inference deployments and routes each request based on cost per token, latency budget, and model strength for the task type. Early customers including teams at Series-B SaaS companies report 30-40% inference cost reductions without measurable quality degradation.
How the router decides
Every incoming request runs through a four-signal classifier in roughly 28 milliseconds: task category (extraction, generation, classification, summarization), prompt token count, declared latency budget, and a recent quality score per backend on similar prompts. The router then routes the request to the cheapest backend that clears the quality bar and meets the latency budget. If the chosen backend returns an error or breaches the deadline, FluxAI silently retries against the second-best option without surfacing the failure to the caller.
"Most teams over-pay for inference because they pin the wrong model to the wrong workload," said the FluxAI team in a launch post. "If you are using Claude Opus for entity extraction or GPT-4 for classification, you are burning budget. Our router fixes that automatically."
Production integration
FluxAI integrates with the OpenAI SDK as a drop-in base URL, so existing applications can adopt it without code changes. Replace https://api.openai.com/v1 with https://api.fluxai.dev/v1 in your SDK initializer and the router transparently dispatches. Token counts, finish_reason, and tool-call payloads come back in the OpenAI schema regardless of which underlying model served the request.
The company offers a free tier covering up to 100,000 requests per month, with paid plans starting at $99/month for production volumes. Enterprise plans add per-tenant isolation, custom routing rules, and a SOC 2 Type II report.
What is next
The team says the next release will add support for embedding models (currently routing only handles chat/completion endpoints) and a fine-tune-aware routing mode where customer-trained adapters get preference for tasks they were tuned on. A Cloudflare-native edge deployment is also in private beta for customers who want to keep request payloads inside their own infrastructure perimeter.
For more information, visit fluxai.dev or read the technical documentation.